

Spis treści
- Czym jest llms.txt i dlaczego nie jest to kolejny robots.txt?
- Jak wygląda poprawna struktura pliku?
- Kiedy llms.txt ma sens, a kiedy nie?
- Jak wdrożyć krok po kroku?
- Wzorce organizacyjne – jak duże firmy strukturyzują swoje pliki
- Narzędzia, które generują llms.txt automatycznie
- Czy llms.txt wpływa na cytowania w AI?
Plik llms.txt to lekki dokument w formacie Markdown umieszczany w katalogu głównym serwera. Wskazuje on botom AI i autonomicznym agentom, co na Twojej stronie jest najważniejsze – bez konieczności przeczesywania setek podstron i renderowania kodu JavaScript. Standard ten zaproponował we wrześniu 2024 roku Jeremy Howard, współtwórca fast.ai i Answer.AI. Prawdziwy przełom nastąpił jednak w listopadzie 2024 roku. Wtedy platforma Mintlify automatycznie wygenerowała te pliki dla tysięcy klientów, w tym dla firm takich jak Anthropic, Cursor i ElevenLabs. Jeśli Twoja strona obsługuje programistów, oferuje API lub chce być gotowa na nadchodzący ekosystem autonomicznych agentów zakupowych, llms.txt to jeden z najtańszych kroków, jakie możesz dziś zrobić.
Czym jest llms.txt i dlaczego nie jest to kolejny robots.txt?
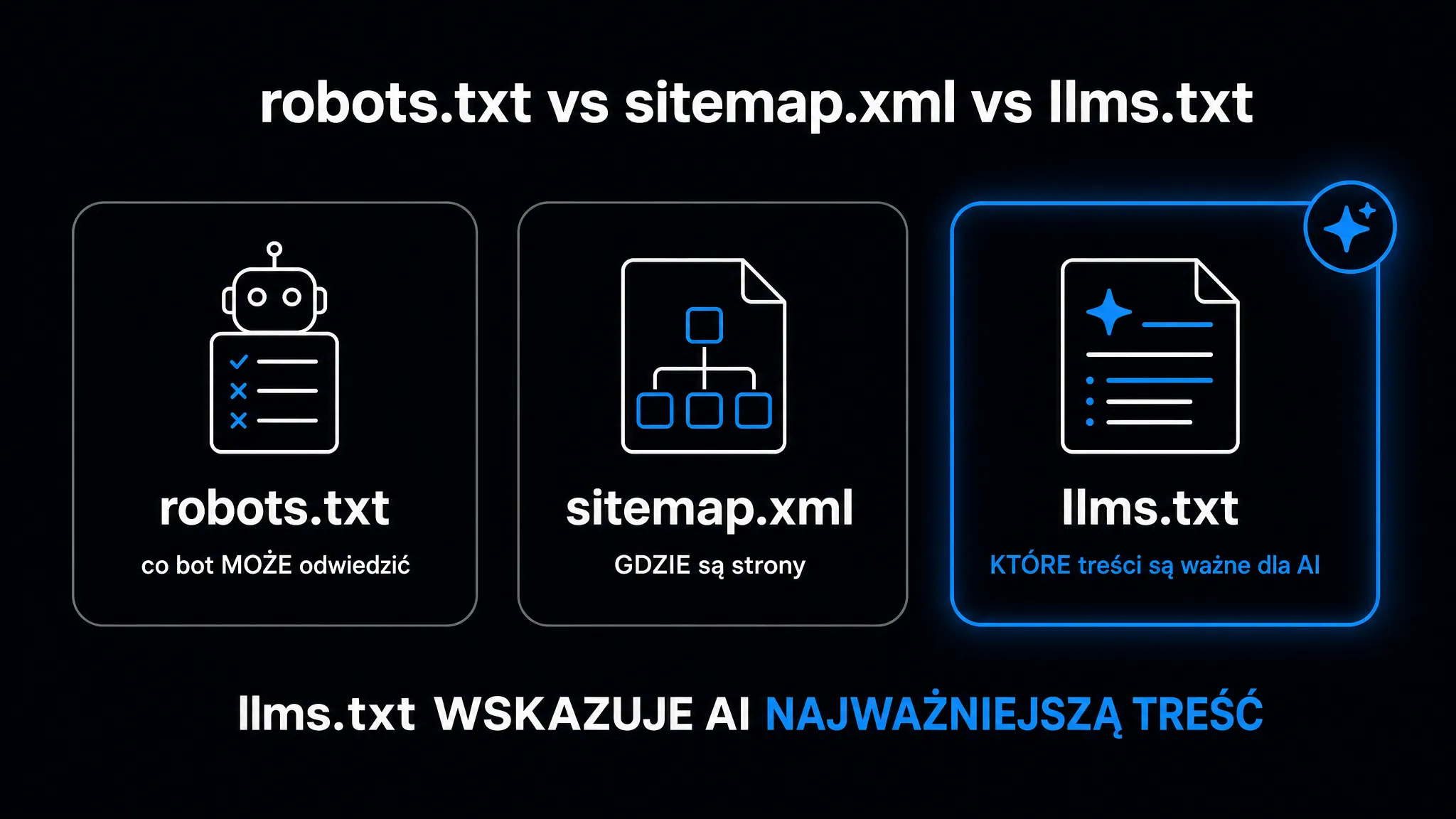
Standard robots.txt liczy sobie trzy dekady i informuje boty indeksujące, jakich ścieżek nie odwiedzać. Plik sitemap.xml wskazuje z kolei, które adresy URL w ogóle istnieją. llms.txt robi coś zupełnie innego. Zamiast kontrolować dostęp, dostarcza kontekst semantyczny. To mapa kluczowych zasobów witryny opisana ludzkim językiem, którą duży model językowy (LLM – Large Language Model) przetwarza błyskawicznie, zamiast analizować kod HTML dziesiątek podstron.
Obok pliku głównego /llms.txt specyfikacja przewiduje uzupełniający plik /llms-full.txt. To skonsolidowane repozytorium wiedzy. Łączy ono całe strony dokumentacyjne lub ofertowe w jeden liniowy dokument pozbawiony menu, CSS i reklam. Systemy RAG (Retrieval-Augmented Generation, czyli generowanie wspomagane wyszukiwaniem) mogą przetworzyć takie repozytorium jednym zapytaniem HTTP zamiast kilkudziesięciu.
Zestawienie trzech standardów pokazuje ich odmienne role – warto je traktować jako uzupełniające się warstwy, a nie konkurencyjne rozwiązania.
| Atrybut | robots.txt | sitemap.xml | llms.txt |
|---|---|---|---|
| Główny odbiorca | Boty indeksujące wyszukiwarek (Googlebot, Bingbot) | Parsery XML wyszukiwarek | LLM-y, agenty autonomiczne, systemy RAG, środowiska IDE z AI |
| Format | Zwykły tekst, dyrektywy Allow/Disallow | XML z metadanymi o priorytecie | Markdown – hierarchiczna struktura semantyczna |
| Cel | Kontrola dostępu, zapobieganie przeciążeniu serwera | Kompletna lista adresów URL | Skondensowany kontekst, eliminacja szumu HTML |
| Status | Standard IETF (RFC 9309) | Powszechnie akceptowany | Nieoficjalny standard społeczności |
llms.txt nie zastępuje żadnego ze starszych standardów. Nakłada na nie warstwę semantyczną przydatną dla maszyn wnioskujących, a nie dla tradycyjnych botów indeksujących.
Jak wygląda poprawna struktura pliku?
Specyfikacja opiera się na hierarchii składni Markdown i wprowadza kilka twardych wymogów. Dokument musi być zapisany w kodowaniu UTF-8. W pierwszej linii zawsze znajduje się nagłówek pierwszego stopnia – to jedyny element absolutnie wymagany przez standard. Bezpośrednio pod nim umieszczasz blok cytatu z precyzyjnym opisem działalności. Zrezygnuj tu z języka marketingowego i wyolbrzymień.
Przykładowa struktura dla agencji SEO oferującej narzędzia SaaS wygląda następująco.
# widocznosc.ai
> Platforma GEO i AEO dla marketerów B2B: audyty widoczności marki w ChatGPT, Claude, Gemini i Perplexity, analiza wskaźnika cytowań (Citation Rate) oraz narzędzia techniczne do optymalizacji pod LLM-y.
## Narzędzia
- [Widoczność marki w AI](https://widocznosc.ai/narzedzia/brand-check): Sprawdza, jak cztery silniki AI opisują Twoją markę na tle kategorii. Zwraca wynik procentowy i gotowe rekomendacje.
- [Dostęp botów AI](https://widocznosc.ai/narzedzia/ai-bots-check): Weryfikuje, które boty AI mają dostęp do domeny i czy robots.txt nie blokuje ich przypadkowo.
- [Ocena cytowalności strony](https://widocznosc.ai/narzedzia/url-check): Analizuje stronę pod kątem 8 czynników cytowalności w LLM-ach w 30 sekund.
## Przewodniki
- [GEO – kompletny przewodnik](https://widocznosc.ai/geo/przewodnik): Czym jest GEO, wyniki badania Princeton KDD 2024, metryki Citation Rate i Share of Voice, strategia wdrożenia na 6 miesięcy.
- [Boty AI – przewodnik](https://widocznosc.ai/geo/boty-ai-przewodnik): Lista user-agentów GPTBot, ClaudeBot, PerplexityBot. Konfiguracja robots.txt i zarządzanie dostępem.
- [llms.txt – wdrożenie](https://widocznosc.ai/geo/llms-txt): Specyfikacja formatu, przykładowa struktura, instrukcja wdrożenia na Cloudflare Pages i Nginx.
## Opcjonalne
- [Polityka prywatności](https://widocznosc.ai/polityka-prywatnosci): Informacje o przetwarzaniu danych osobowych.
- [Changelog narzędzi](https://widocznosc.ai/changelog): Historia aktualizacji platformy.Poznaj kilka reguł technicznych, które decydują o poprawności analizy składniowej.
- Nagłówek H1 – tylko jeden, w pierwszej linii pliku, określa nazwę marki lub projektu
- Blok cytatu (
>) – bezpośrednio pod H1, syntetyczny opis bez przymiotników wartościujących - Sekcje H2 – grupują linki tematycznie, a każda pozycja zawiera absolutny adres HTTPS i mikrostreszczenie
- Sekcja
## Opcjonalne– modele operujące w trybie ograniczonego okna kontekstowego pomijają linki z tej sekcji, więc trafiają tu polityki prywatności, changelogi i archiwa - Host-scoping – plik umieszczony pod
example.com/llms.txtobejmuje wyłącznie tę domenę, dlatego subdomeny wymagają osobnych plików
Kiedy llms.txt ma sens, a kiedy nie?
To pytanie mocno dzieli rynek. Odpowiedź zależy od tego, kto jest Twoim faktycznym odbiorcą.
Google Search oficjalnie odrzucił ten standard. John Mueller z Google wskazał na ryzyko tak zwanego AI cloakingu – sytuacji, w której boty otrzymują idealnie zoptymalizowany plik tekstowy, a użytkownicy końcowi widzą inną treść. Badania SE Ranking potwierdzają brak korelacji między obecnością llms.txt a cytowaniami w ChatGPT czy Gemini. Jeśli Twoim celem jest wyłącznie widoczność w AI Overviews od Google lub w odpowiedziach ChatGPT w trybie przeglądarkowym, ten plik nie zmieni Twoich statystyk GEO.
Zupełnie inaczej sytuacja wygląda w ekosystemie deweloperskim. Środowiska takie jak Cursor, Windsurf czy Bolt.new natywnie pobierają llms.txt przy mapowaniu zewnętrznych bibliotek. Brak tego pliku zmusza asystentów AI do chaotycznego pobierania kodu HTML. To drastycznie zwiększa zużycie tokenów i pogarsza jakość generowanego kodu. Jeśli Twój produkt jest biblioteką, API lub platformą dokumentacji, ten plik jest praktycznie obowiązkowy.
Najsilniejszy argument za wdrożeniem to Google Lighthouse 13.3. Ta wersja wprowadziła eksperymentalną kategorię audytów Agentic Browsing, która ocenia gotowość witryny do obsługi autonomicznych agentów realizujących zadania bezpośrednio na stronach. Obecność poprawnego llms.txt to jeden z kluczowych czynników oceny dojrzałości agentowej serwisu.
Zobacz trzy scenariusze, w których wdrożenie jest opłacalne, oraz jeden, w którym możesz je pominąć.
- Firma technologiczna lub dostawca API – kosztem zbliżonym do zera drastycznie poprawiasz komfort programistów korzystających z Twojej dokumentacji w asystentach AI
- Platforma e-commerce z myślą o przyszłości – autonomiczne agenty zakupowe (shopping agents) działające w przeglądarkach będą pobierać
llms.txt, zanim wykonają akcję na stronie - Witryna celująca w audyt Lighthouse – każda strona, która chce pozytywnie przejść test Agentic Browsing w wersji 13.3
- Landing page bez komponentu technicznego – tu możesz pominąć wdrożenie, jeśli Twoim celem jest wyłącznie widoczność w tradycyjnym SEO i AI Overviews Google
Jak wdrożyć krok po kroku?
Samo napisanie pliku to mniej niż połowa pracy. Serwer musi go poprawnie serwować – z właściwym typem MIME i nagłówkami ułatwiającymi wykrywanie zasobów.
Krok 1 – napisz plik zgodny ze specyfikacją
Zacznij od sekcji, które faktycznie odwiedzają boty. Skup się na stronach produktowych, dokumentacji API i kluczowych przewodnikach. Opisy po myślniku mają być mikrostreszczeniami – konkretną odpowiedzią na pytanie, jakie problemy użytkownika rozwiązuje dany zasób. Unikaj przymiotników marketingowych. Modele wykazują wyższą precyzję wnioskowania przy twardych danych liczbowych i konkretnych parametrach technicznych.
Gotowy plik umieść jako public/llms.txt (Astro, Next.js, Nuxt) lub w katalogu głównym serwera plików statycznych.
Krok 2 – skonfiguruj nagłówki HTTP dla wykrywania zasobów
Boty AI mogą wykryć dostępność pliku bez odpytywania domeny w ciemno, jeśli serwer dołącza odpowiednie nagłówki HTTP. Konfiguracja dla Nginx wygląda następująco.
server {
add_header Link "</llms.txt>; rel=\"llms-txt\", </llms-full.txt>; rel=\"llms-full-txt\"" always;
add_header X-Llms-Txt "/llms.txt" always;
location = /llms.txt {
default_type text/plain;
charset utf-8;
}
}Na Cloudflare Pages nagłówki konfigurujesz w pliku _headers w katalogu głównym.
/*
Link: </llms.txt>; rel="llms-txt"
X-Llms-Txt: /llms.txtKrok 3 – zadbaj o negocjację zawartości (opcjonalnie, ale warte rozważenia)
Zaawansowane podejście polega na tym, że boty mogą żądać wersji Markdown dowolnego adresu URL przez nagłówek Accept: text/markdown. Serwer odpowiednio kieruje żądanie i zamiast kodu HTML zwraca czysty plik .md. W przypadku żądań nieobsługiwanych typów dokumentów serwer zwraca kod HTTP 406 (Not Acceptable). To znacznie wykracza poza podstawowe wdrożenie. Warto jednak znać ten mechanizm, jeśli budujesz architekturę pod kątem pełnej kompatybilności agentowej.
Wzorce organizacyjne – jak duże firmy strukturyzują swoje pliki
Firmy, które wdrożyły ten standard, wypracowały kilka podejść architektonicznych. Wybór zależy od skomplikowania Twojego ekosystemu informacyjnego.
- Index + Full Export – lekki indeks
/llms.txtodsyłający do skonsolidowanego/llms-full.txt, co stanowi optymalny podział dla asystentów czatowych (pobierają indeks) i systemów RAG (pobierają pełny eksport); stosowany przez Anthropic, Perplexity i LangGraph - Product-First – struktura zorganizowana wokół linii produktowych i kluczowych scenariuszy wdrożeniowych, zapewniająca intuicyjną nawigację dla modeli próbujących dopasować produkt do zapytania; stosowana przez platformy Vercel i Mintlify
- API-Centric Catalog – kategoryzacja oparta na zasobach API, metodach autoryzacji i schematach danych, która pozwala modelom konstruować zapytania do API bez pobierania setek podstron; stosowana przez Stripe i ElevenLabs
- Workflow-First – układ zorientowany na cykl życia dewelopera, obejmujący konfigurację, wdrożenie i rozwiązywanie problemów; stosowany przez Cursor, Windsurf oraz Bolt.new
- Orientation-Focused – architektura głęboko segmentowana pionowo lub podzielona na osobne pliki dla różnych technologii, rozwiązująca problem orientacji w ogromnych ekosystemach; stosowana przez Cloudflare i Supabase
Dla prostych witryn firmowych optymalny jest wzorzec Product-First. Z kolei dla rozbudowanych serwisów deweloperskich standardem staje się podejście Index + Full Export.
Narzędzia, które generują llms.txt automatycznie
Ręczne utrzymywanie spójności pliku przy dynamicznie zmieniającej się strukturze serwisu pochłania czas i zasoby. Dlatego warto znać narzędzia, które automatyzują ten etap.
- llmstxt by Firecrawl – pobiera
sitemap.xmli generuje plik na podstawie głębokiego przeszukiwania stron, co stanowi dobry punkt startowy dla serwisów bez dokumentacji w repozytorium - aircodelabs/llms-txt-generator – generuje pliki dokumentacyjne kodu źródłowego i uruchamia lokalny serwer MCP (Model Context Protocol), umożliwiający integrację z Cursorem i Claude Desktop
- llmrefs.com Generator – platforma SaaS przeprowadzająca automatyczny audyt domeny, która używa modelu generatywnego do napisania mikrostreszczenia dla każdego linku
- llm-docs-builder – optymalizuje surowe pliki Markdown pod systemy RAG i automatycznie kompiluje plik indeksowy, co przydaje się w projektach opartych na statycznych generatorach stron
Dla projektów z dużą częstotliwością aktualizacji – takich jak dokumentacje techniczne czy platformy SaaS z regularnie zmienianą ofertą – zaleca się integrację generatora CLI bezpośrednio do potoku CI/CD. Dzięki temu plik serwowany maszynom nigdy nie prezentuje nieaktualnego stanu wiedzy o systemie.
Czy llms.txt wpływa na cytowania w AI?
Bezpośrednio – nie, przynajmniej na razie. Badania i dane z logów serwerowych są jednoznaczne. Tradycyjne wyszukiwarki i systemy generujące AI Overviews nie pobierają tego pliku przy konstruowaniu odpowiedzi. Jeśli Twoim jedynym celem jest poprawa wskaźnika cytowań (Citation Rate) w ChatGPT czy Gemini, tutaj największe znaczenie mają inne czynniki cytowalności – gęstość faktograficzna treści, dane strukturalne schema.org oraz spójność informacji w sieci.
llms.txt odgrywa natomiast wyraźną rolę pośrednią. Po pierwsze, asystenci kodowania – Cursor, Copilot, Claude – mogą korzystać z tego pliku przez integracje MCP lub po ręcznym wskazaniu adresu URL przy mapowaniu Twojej biblioteki lub API. To bezpośrednio zwiększa jakość kodu generowanego przez użytkowników Twojego produktu. Po drugie, pozytywny wynik audytu Agentic Browsing w Lighthouse 13.3 zabezpiecza widoczność witryny w przeglądarkach, które w kolejnych latach będą realizowały zakupy i wyszukiwały oferty w imieniu użytkowników.
Koszt wdrożenia wynosi zaledwie kilka godzin pracy. Bezpośrednie korzyści są na razie niszowe, ale gotowość agentowa może okazać się decydująca w perspektywie 18–24 miesięcy. To stosunek nakładu pracy do potencjalnych zysków, który warto ocenić samodzielnie.
Jeśli chcesz sprawdzić, czy Twoja strona jest już teraz dostępna dla botów AI – takich jak GPTBot, ClaudeBot czy PerplexityBot – narzędzie Dostęp botów AI weryfikuje konfigurację robots.txt i dostęp botów w kilkanaście sekund. To świetny punkt startowy przed wdrożeniem llms.txt. Nie ma przecież sensu budować mapy zasobów dla botów, które i tak są zablokowane na poziomie serwera. Szerszy kontekst techniczny – dlaczego każdy z tych botów ma inny user-agent i jak nimi zarządzać – opisuje przewodnik po botach AI. Natomiast jeśli chcesz zrozumieć, jakie czynniki faktycznie decydują o cytowaniach Twojej marki w LLM-ach, zacznij od przewodnika GEO. Znajdziesz tam wyniki badania Princeton KDD 2024 i konkretne taktyki z mierzalnymi efektami.
Często zadawane pytania o llms.txt
Czy llms.txt zastępuje robots.txt?
llms.txt zastępuje robots.txt?robots.txt kontroluje dostęp botów indeksujących do zasobów serwera – jest standardem oficjalnym od 1994 roku, ratyfikowanym przez IETF w RFC 9309. llms.txt dostarcza semantyczny kontekst modelom językowym i agentom AI. Oba pliki powinny istnieć równolegle; jeden nie wyklucza drugiego.Co powinno znaleźć się w sekcji ## Opcjonalne?
## Opcjonalne?Czy subdomeny potrzebują osobnych plików?
llms.txt obowiązuje wyłącznie dla domeny, na której jest umieszczony, zgodnie z RFC 3986 (Host-Scoping). Plik pod example.com/llms.txt nie obejmuje shop.example.com ani docs.example.com. Każda subdomena reprezentująca odrębny produkt powinna serwować własny plik.Czy mogę wdrożyć llms.txt na Shopify?
llms.txt na Shopify?/llms.txt → ten adres URL. Agenty AI odpytujące domenę główną zostaną prawidłowo przekierowane do zasobu.




