

Spis treści
- Dlaczego silniki RAG potrzebują danych strukturalnych?
- Typy encji i kiedy ich używać
- Implementacja @graph – spójna sieć encji
- Atrybut sameAs – cyfrowy paszport encji
- FAQPage – bezpośrednia ekstrakcja odpowiedzi
- Ścieżka wdrożenia i narzędzia diagnostyczne
- HowTo – struktura pod zapytania instrukcyjne
- Jak LLM-y różnie interpretują schema.org?
Dane strukturalne w formacie JSON-LD (JavaScript Object Notation for Linked Data) przestały być technicznym dodatkiem poprawiającym gwiazdki w wynikach wyszukiwania. W erze GEO (Generative Engine Optimization, czyli optymalizacji pod generatywne silniki wyszukiwania) to fundament, na którym LLM-y (Large Language Models, czyli duże modele językowe) budują zrozumienie encji – marek, autorów, produktów – i decydują, czy cytować Twoją stronę w syntezie odpowiedzi. Badanie Otterly.ai z okresu grudzień 2025–marzec 2026 wykazało, że witryny z poprawnym schema.org notują wzrost obecności w boksach Google AI Overviews o 1500% w ciągu zaledwie trzech miesięcy. Ten artykuł pokazuje, jak to wdrożyć krok po kroku.
Dlaczego silniki RAG potrzebują danych strukturalnych?
Systemy takie jak Google AI Overviews czy Perplexity nie czytają stron jak człowiek. Działają na zasadzie RAG (Retrieval-Augmented Generation, czyli generowania wspomaganego wyszukiwaniem) – dynamicznie pobierają fragmenty tekstu, zamieniają je w wektory liczbowe i wyszukują te, które semantycznie odpowiadają zapytaniu użytkownika.
Surowy HTML to dla parserów AI bariera. Bot musi poświęcić zasoby obliczeniowe na odróżnienie nagłówka nawigacyjnego od treści merytorycznej, reklamy od definicji, stopki od podsumowania artykułu. Schema.org w formacie JSON-LD działa jak interfejs semantyczny: eliminuje domysły, jednoznacznie etykietuje każdy obiekt na stronie i redukuje liczbę przetwarzanych tokenów przypadających na jedną encję – według badań konsorcjum Data World nawet 2–5-krotnie. Strony z bezbłędną implementacją schema.org są trzy razy częściej wybierane jako źródło w odpowiedziach generatywnych niż strony oparte wyłącznie na nieoznaczonym tekście.
Istotna jest tu też architektura Resource Description Framework (RDF), na której opiera się standard schema.org. RDF definiuje dane jako trójki podmiot–predykat–obiekt, co pozwala modelom AI mapować encje na globalne identyfikatory zamiast interpretować je za każdym razem od nowa z kontekstu.
Jak schema.org trafia do systemów RAG?
Bezpośrednia odpowiedź jest nieintuicyjna: większość platform AI (z wyjątkiem Gemini) nie odczytuje JSON-LD na żywo podczas generowania odpowiedzi. Eksperyment Otterly.ai – siedem platform testowanych przez 90 dni – wykazał, że 6 z 7 silników nie potrafi bezpośrednio zinterpretować kodu JSON-LD w oknie czatu. Jedynie Gemini ekstrahuje atrybuty schematu w czasie rzeczywistym.
Wpływ schema.org jest zatem pośredni, ale decydujący. ChatGPT Search, Perplexity i Microsoft Copilot odpytują tradycyjne indeksy wyszukiwarek – przede wszystkim Bing i Google – i syntetyzują odpowiedzi na bazie stron, które tam się znalazły. Schema.org ułatwia robotom indeksującym precyzyjną klasyfikację strony, co przekłada się na lepszą widoczność w tych indeksach wejściowych, a przez to – na większe szanse pojawienia się w puli źródeł dla silnika AI.
Typy encji i kiedy ich używać
Wybór właściwego typu schema to nie formalność – to instrukcja dla modelu, jak zaklasyfikować Twoją stronę i jakie pytania może ona obsłużyć. Poniższa tabela zbiera typy najistotniejsze z perspektywy GEO wraz z ich zastosowaniem.
Jedna zasada krytyczna przed tabelą: nie stosuj typów „na wyrost”. FAQPage bez rzeczywistych par pytanie–odpowiedź w HTML-u lub Product bez ceny i dostępności obniżają wiarygodność encji w oczach walidatorów Google – a te same sygnały trafiają do systemów oceniających strony pod AI Overviews.
| Typ schema.org | Kiedy stosować | Najważniejsze atrybuty w GEO |
|---|---|---|
Organization | Każda strona firmowa, strona główna | name, url, sameAs, logo |
Person | Strony autorów, biogramy, profile ekspertów | name, jobTitle, sameAs, worksFor |
BlogPosting / Article | Artykuły, wpisy blogowe, analizy | headline, author, datePublished, about |
FAQPage | Strony z sekcją pytań i odpowiedzi | mainEntity z parami Question–Answer |
HowTo | Przewodniki krokowe, tutoriale techniczne | step z HowToStep, name, description |
Product | Karty produktów e-commerce | name, offers, aggregateRating |
WebPage | Strony docelowe, landing page | name, url, isPartOf, breadcrumb |
BreadcrumbList | Nawigacja okruszkowa | itemListElement z ListItem |
Szczególną uwagę zwróć na BlogPosting i Article – to typy, którymi Google klasyfikuje treści informacyjne do AI Overviews. Brak atrybutu author z poprawnym @id wskazującym na encję Person to jedna z najczęstszych przyczyn, dla których strony z wartościową treścią są pomijane przez system.
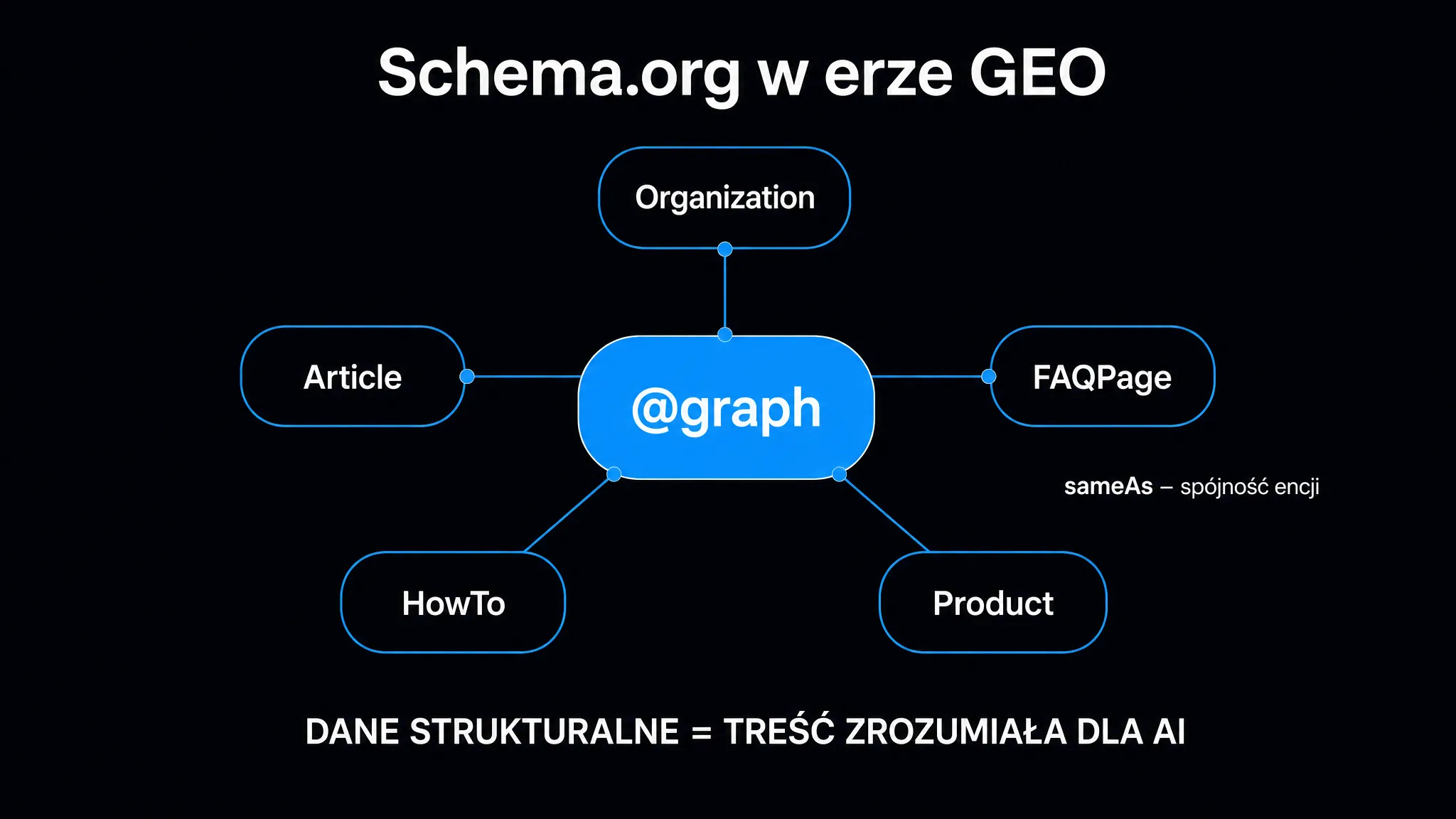
Implementacja @graph – spójna sieć encji
Największy błąd, jaki widujemy w audytach technicznych ICEA, to wdrożenie schema.org jako izolowanych bloków: jeden skrypt dla Organization, drugi dla BlogPosting, bez żadnych połączeń między nimi. Silniki AI budują zrozumienie stron na podstawie relacji – nie izolowanych tagów.
Format @graph pozwala zadeklarować wiele encji w jednym bloku JSON-LD i powiązać je przez unikalne identyfikatory @id. Każdy @id to globalnie unikalny URI – adres URL fragmentu strony lub encji – który model może zweryfikować i zapamiętać. Poniżej kompletny szablon dla artykułu blogowego:
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://twojadomena.pl/#organization",
"name": "Nazwa Firmy",
"url": "https://twojadomena.pl",
"logo": {
"@type": "ImageObject",
"url": "https://twojadomena.pl/assets/logo.png",
"width": 512,
"height": 512
},
"sameAs": [
"https://www.wikidata.org/wiki/QXXXXXXX",
"https://www.linkedin.com/company/nazwa-firmy",
"https://pl.wikipedia.org/wiki/Nazwa_Firmy"
]
},
{
"@type": "Person",
"@id": "https://twojadomena.pl/autorzy/jan-kowalski/#author",
"name": "Jan Kowalski",
"jobTitle": "Head of SEO",
"worksFor": {
"@id": "https://twojadomena.pl/#organization"
},
"sameAs": [
"https://www.linkedin.com/in/jan-kowalski-seo",
"https://orcid.org/0000-0000-0000-0000"
]
},
{
"@type": "BlogPosting",
"@id": "https://twojadomena.pl/blog/przykladowy-artykul/#post",
"isPartOf": {
"@type": "WebPage",
"@id": "https://twojadomena.pl/blog/przykladowy-artykul/"
},
"headline": "Tytuł artykułu – konkretny i oparty na pytaniu użytkownika",
"description": "Opis meta 150–160 znaków z główną korzyścią dla czytelnika.",
"datePublished": "2026-05-25T09:00:00+02:00",
"dateModified": "2026-05-25T09:00:00+02:00",
"author": {
"@id": "https://twojadomena.pl/autorzy/jan-kowalski/#author"
},
"publisher": {
"@id": "https://twojadomena.pl/#organization"
},
"about": {
"@type": "Thing",
"name": "Schema.org",
"sameAs": "https://schema.org"
},
"inLanguage": "pl-PL"
}
]
}Zwróć uwagę na kilka kluczowych elementów. worksFor w encji Person wskazuje nie na URL, ale na @id encji Organization – model może wtedy połączyć autora z wydawcą jako jedną spójną sieć. about w BlogPosting opisuje temat artykułu jako encję z własnym sameAs – to bezpośredni sygnał dla Knowledge Graph Google, o czym jest ta strona.
Atrybut sameAs – cyfrowy paszport encji
sameAs to najprawdopodobniej najbardziej niedoceniany atrybut w całym schema.org. Dla systemów AI jest dowodem tożsamości: mówi modelowi, że encja „Firma X” ze strony twojadomena.pl to ta sama encja, która jest opisana w Wikidata pod identyfikatorem QXXXXXXX, na Wikipedii pod nazwą „Firma X” i na LinkedIn pod adresem /company/firma-x.
Bez sameAs model traktuje Twoją markę jako anonimowy ciąg znaków. Nie może jej połączyć z wiedzą, którą posiada z danych treningowych ani z Grafu Wiedzy. W efekcie: nawet jeśli artykuł merytoryczny jest doskonały, model nie jest w stanie przypisać autorytetu tematycznego do konkretnego podmiotu.
Priorytetowe zewnętrzne bazy referencyjne dla sameAs:
- Wikidata – pierwszy wybór, bo Wikidata bezpośrednio zasila Knowledge Graph Google. Każda firma, osoba i produkt może mieć tam swój wpis.
- Wikipedia – sygnał bardzo silny, ale wymaga encyklopedyczności (weryfikowalnej rozpoznawalności). Nie twórz wpisów, które mogą zostać usunięte.
- LinkedIn – dla encji
PersoniOrganization; uwiarygodnia profesjonalny kontekst. - ORCID – dla autorów naukowych i analityków; silny sygnał E-E-A-T w tematach wymagających wiedzy eksperckiej.
- Crunchbase – dla firm technologicznych i startupów.
Różne platformy AI inaczej walidują encje. Google Gemini i AI Overviews są oparte bezpośrednio na Knowledge Graph – sameAs do Wikidata ma tu decydujące znaczenie. ChatGPT Search natomiast przykłada dużą wagę do obecności w Wikipedii, Reddicie i głównych mediach z baz treningowych. Perplexity ceni aktualność – encje wzmiankowane w źródłach z ostatnich 30 dni mają wyższy priorytet przy warstwie pobierania danych.
FAQPage – bezpośrednia ekstrakcja odpowiedzi
Schemat FAQPage wykazuje najwyższą korelację ze wzrostem widoczności w boksach AI Overviews spośród wszystkich typów schema.org. Powód jest mechaniczny: system AI Overviews jest zoptymalizowany pod bezpośrednią ekstrakcję odpowiedzi z par pytanie–odpowiedź, a FAQPage dostarcza dokładnie tę strukturę w postaci jednoznacznych węzłów semantycznych.
Warunek konieczny: każda para pytanie–odpowiedź musi być obecna w widocznym HTML-u strony, nie tylko w JSON-LD. Google waliduje spójność między schematem a treścią. Jeśli JSON-LD deklaruje FAQPage z pięcioma pytaniami, ale HTML zawiera tylko jedno zwinięte <details>, walidator odrzuci schemat jako niezgodny.
Poprawna implementacja FAQPage jako część @graph:
{
"@type": "FAQPage",
"@id": "https://twojadomena.pl/blog/przykladowy-artykul/#faq",
"mainEntity": [
{
"@type": "Question",
"name": "Ile czasu zajmuje wdrożenie schema.org?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Podstawowy pakiet – Organization, BlogPosting, BreadcrumbList – można wdrożyć w jeden dzień roboczy dla istniejącej strony. Pełna implementacja z FAQPage i HowTo dla wszystkich kluczowych podstron to 2–4 tygodnie, zależnie od liczby szablonów CMS."
}
},
{
"@type": "Question",
"name": "Czy schema.org wpływa bezpośrednio na cytowania w ChatGPT?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Wpływ jest pośredni. ChatGPT Search pobiera strony z indeksu Bing i Google. Schema.org poprawia klasyfikację strony w tych indeksach, co zwiększa prawdopodobieństwo włączenia jej do puli źródeł syntezy AI."
}
}
]
}Odpowiedź w polu text powinna mieć 40–60 słów – wystarczająco szczegółowa, żeby model mógł ją zacytować wprost, ale wystarczająco zwięzła, żeby zmieścić się w boksie AI Overviews bez przycinania.
Jeśli chcesz sprawdzić, jak Twoja istniejąca treść wypada pod kątem cytowalności przed wdrożeniem schematu, Ocena cytowalności strony w kilkanaście sekund analizuje stronę pod kątem gotowości do cytowania przez silniki AI.
Ścieżka wdrożenia i narzędzia diagnostyczne
Implementacja schema.org bez procesu weryfikacji prowadzi wprost do drugiego błędu opisanego powyżej. Prawidłowy protokół wdrożenia składa się z czterech etapów.
Etap 1 – inwentaryzacja szablonów. Zidentyfikuj wszystkie typy stron w witrynie: strona główna, strony kategorii, artykuły, strony autorów, strony produktów. Dla każdego szablonu zaplanuj odpowiedni typ schema – jeden szablon może generować dziesiątki lub setki podstron, więc błąd w szablonie mnoży się przez liczbę stron.
Etap 2 – implementacja w jednym bloku @graph. Zamiast wielu osobnych skryptów JSON-LD, twórz jeden blok @graph na stronę. Redukuje to ryzyko konfliktów między deklaracjami i ułatwia walidację.
Etap 3 – walidacja w Google Rich Results Test. Narzędzie dostępne pod adresem search.google.com/test/rich-results pokazuje, które typy schema zostały wykryte i czy dane zostaną zakwalifikowane do wyświetlenia jako wyniki rozszerzone. Każdy błąd w tym widoku to potencjalna blokada dla AI Overviews.
Etap 4 – monitoring w Google Search Console. Raport „Ulepszenia” w GSC agreguje błędy schema wykryte przez Googlebota na wszystkich zaindeksowanych stronach. Skonfiguruj alerty e-mail dla nowych błędów – zmiana szablonu CMS lub aktualizacja wtyczki często psuje schema.org bez żadnej widocznej zmiany w wyglądzie strony.
Narzędzia diagnostyczne warte uwagi w codziennej pracy:
- Google Rich Results Test – walidacja poszczególnych URL-i, bezpłatne
- Schema Markup Validator (
validator.schema.org) – weryfikacja zgodności ze specyfikacją schema.org, niezależna od Google - Screaming Frog SEO Spider – masowe skanowanie i ekstrakcja wszystkich bloków JSON-LD z całej witryny do CSV
- GSC API – automatyczny eksport błędów schema do monitoringu ciągłego
Szczegółowe zasady konfiguracji pliku robots.txt i zarządzania dostępem botów AI do Twojej witryny opisuje artykuł o botach AI – warto zacząć od niego, zanim zainwestujesz czas w schema.org, bo blokada bota na poziomie robots.txt uniemożliwia indeksowanie i czyni schemat bezużytecznym.
HowTo – struktura pod zapytania instrukcyjne
Typ HowTo jest niedoceniany w polskim ekosystemie SEO, podczas gdy w systemach AI odpowiada bezpośrednio za obsługę zapytań typu „jak wdrożyć”, „jak skonfigurować”, „krok po kroku”. Perplexity i Google AI Overviews preferują HowTo dla zapytań instrukcyjnych – wyciągają z niego poszczególne kroki jako gotowe fragmenty odpowiedzi.
Schemat HowTo wymaga listy kroków jako obiektów HowToStep z atrybutami name (nagłówek kroku), text (opis) i opcjonalnie image (zdjęcie lub ilustracja). Każdy krok powinien być samodzielny – model może zaprezentować wybrane kroki bez całego schematu.
{
"@type": "HowTo",
"@id": "https://twojadomena.pl/blog/wdrozenie-schema/#howto",
"name": "Jak wdrożyć schema.org w formacie JSON-LD",
"description": "Krok po kroku: od inwentaryzacji szablonów do walidacji w Google Search Console.",
"totalTime": "PT4H",
"step": [
{
"@type": "HowToStep",
"position": 1,
"name": "Zinwentaryzuj typy stron w witrynie",
"text": "Wypisz wszystkie unikalne szablony: strona główna, kategorie, artykuły, autorzy, produkty. Dla każdego szablonu przypisz typ schema.org z tabeli powyżej."
},
{
"@type": "HowToStep",
"position": 2,
"name": "Zaimplementuj @graph w sekcji <head>",
"text": "Wstaw jeden blok JSON-LD z deklaracją @graph na szablon. Połącz encje przez @id – Organization, Person i BlogPosting powinny tworzyć spójną sieć relacji."
},
{
"@type": "HowToStep",
"position": 3,
"name": "Zwaliduj każdy szablon w Rich Results Test",
"text": "Wklej URL do narzędzia Google Rich Results Test. Usuń wszystkie błędy krytyczne przed wdrożeniem produkcyjnym. Ostrzeżenia możesz stopniowo korygować."
},
{
"@type": "HowToStep",
"position": 4,
"name": "Skonfiguruj monitoring w Google Search Console",
"text": "Sprawdź raport Ulepszenia w GSC po 7–14 dniach od wdrożenia. Skonfiguruj powiadomienia e-mail dla nowych błędów schema. Monitoruj wzrost liczby stron zakwalifikowanych do Rich Results."
}
]
}Atrybut totalTime w formacie ISO 8601 (np. PT4H dla czterech godzin) pojawia się bezpośrednio w rozszerzonych wynikach Google i silnie zwiększa CTR dla zapytań z intencją instrukcyjną. To jeden z prostych elementów, które większość implementacji pomija.
Jeśli budujesz spójną strategię GEO wykraczającą poza dane strukturalne, kompleksowy przewodnik GEO opisuje pełną metodykę – od audytu technicznego przez optymalizację treści po monitoring Share of Voice. Warto też zapoznać się z artykułem o llms.txt, który uzupełnia schema.org o bezpośredni kanał komunikacji z modelami AI odpytującymi Twoją domenę.
Jak LLM-y różnie interpretują schema.org?
Nie istnieje jedna „poprawna” implementacja schema.org – różne silniki AI inaczej walidują i wykorzystują dane strukturalne. Rozumienie tych różnic pozwala ustalić priorytety wdrożenia.
Poniższa lista porządkuje zachowanie głównych platform – na podstawie eksperymentu Otterly.ai oraz obserwacji z audytów ICEA:
- Google Gemini – jedyna platforma, która odczytuje JSON-LD bezpośrednio w czasie rzeczywistym (AI Overviews korzysta ze schematu pośrednio, przez indeks Google). Bez poprawnego
sameAsdo Wikidata marka nie zostanie połączona z Knowledge Graph i jej cytowania są przypadkowe, a nie systematyczne. - ChatGPT Search (OAI-SearchBot) – odpytuje indeks Bing; schema.org wpływa na klasyfikację w Bing, co przekłada się na widoczność w ChatGPT pośrednio. Wysoka waga
ArticleiBlogPostingz kompletnymauthor. - Perplexity (PerplexityBot) – indeksuje w czasie zbliżonym do rzeczywistego;
dateModifiedwBlogPostingjest aktywnie weryfikowany – artykuły aktualizowane w ciągu ostatnich 30 dni mają trzykrotnie wyższy wskaźnik cytowań. - Microsoft Copilot – oparty na silniku Bing; analogiczne priorytety jak w ChatGPT Search, ale silniejszy nacisk na
BreadcrumbListjako sygnał struktury witryny. - Claude (Claude-SearchBot) – w trybie wyszukiwania odpytuje zewnętrzne źródła; schema.org wpływa przez jakość klasyfikacji w indeksach wejściowych. Więcej o tym, jak cytowania trafiają do odpowiedzi modeli, opisuje artykuł o tym, jak LLM-y cytują źródła.
Priorytet jest jasny: wdrożenie Organization z sameAs do Wikidata, BlogPosting z kompletnym author i FAQPage tam, gdzie masz sekcję FAQ. To trzy typy, które przynoszą największy zwrot dla większości witryn B2B i contentowych – i właśnie od nich warto zacząć.





