

Spis treści
ChatGPT to interfejs konwersacyjny zbudowany na modelach z rodziny GPT (Generative Pre-trained Transformer) – dużych modelach językowych (LLM, Large Language Model) opracowanych przez OpenAI. Od publicznego debiutu w listopadzie 2022 roku zgromadził milion użytkowników w pięć dni. Sto milionów osiągnął w dwa miesiące. Zrobił to szybciej niż jakakolwiek inna aplikacja w historii. Jeśli dopiero zaczynasz pracę z AI lub chcesz wreszcie zrozumieć, co kryje się za tym oknem czatu, ten przewodnik wyjaśnia mechanizm, możliwości i realne ograniczenia. Bez skrótów. Bez żargonu, który więcej ukrywa, niż tłumaczy.
Czym jest ChatGPT i jak wpisuje się w ekosystem OpenAI?
OpenAI to laboratorium badań nad sztuczną inteligencją założone w 2015 roku z misją rozwoju AI dla dobra ogółu. ChatGPT nie jest jedynym produktem firmy – to raczej najbardziej widoczna warstwa potężnego ekosystemu. Obejmuje on modele, interfejsy programistyczne i wyspecjalizowane narzędzia.
Uporządkujmy te pojęcia na samym wstępie:
- GPT – seria modeli językowych (GPT-3, GPT-4, a obecnie rodzina GPT-5); sam model to „silnik”, który przetwarza tekst
- ChatGPT – produkt konsumencki, interfejs czatu dostępny pod adresem chat.openai.com, napędzany aktualnym modelem GPT
- OpenAI API – programistyczny dostęp do modeli GPT, GPT Image i innych, używany przez deweloperów do budowy własnych aplikacji
- GPT Image – model do generowania obrazów z opisu tekstowego, wbudowany w ChatGPT (zastąpił DALL-E pod koniec 2025 roku)
- Whisper – model do transkrypcji i tłumaczenia mowy
ChatGPT działa w przeglądarce i aplikacji mobilnej, a od 2023 roku również jako wtyczka i element Microsoft 365 Copilot. OpenAI udostępnia swoje modele przez API, co pozwala firmom zewnętrznym wbudowywać je we własne produkty. Właśnie dlatego technologia ta pojawia się pośrednio w Bingu, narzędziach do pisania, systemach obsługi klienta i dziesiątkach innych miejsc.
W kontekście widoczności marki w wyszukiwarkach AI: pełny obraz tego, co GPT „wie” o Twojej firmie i skąd czerpie tę wiedzę, opisuje przewodnik po modelach LLM. To doskonały punkt wyjścia przed startem optymalizacji.
Jak działa model GPT, od tokenów po odpowiedź?
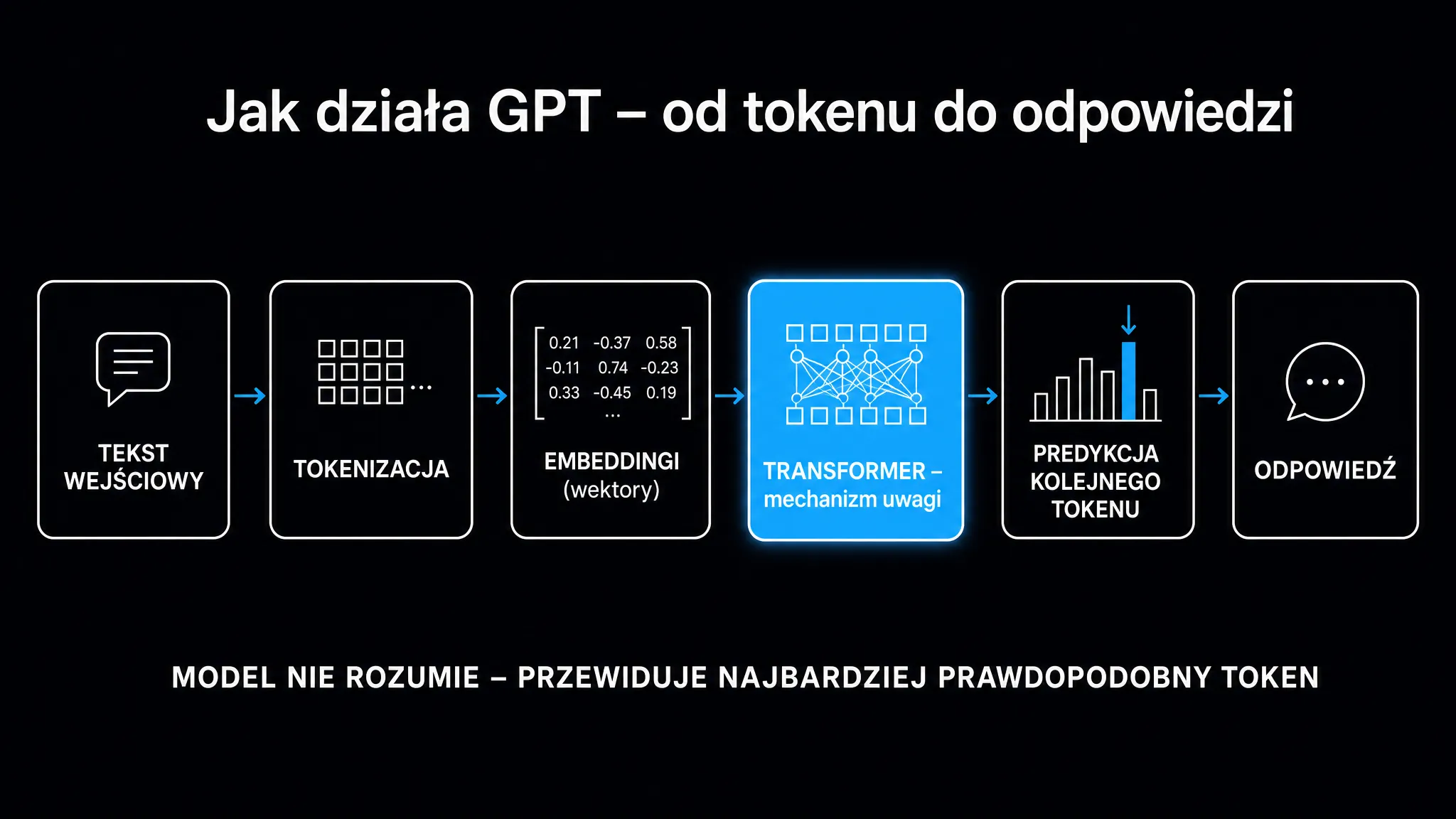
ChatGPT nie „szuka” odpowiedzi w bazie danych ani nie „pamięta” faktów jak encyklopedia. Generuje tekst token po tokenie. Za każdym razem przewiduje, jaka sekwencja znaków jest najbardziej prawdopodobna w danym kontekście. To subtelna, ale fundamentalna różnica.
Model opiera się na architekturze typu Transformer – typie sieci neuronowej zaprezentowanym w pracy „Attention is All You Need” (Vaswani et al., 2017). Wcześniejsze systemy przetwarzały tekst sekwencyjnie, czyli słowo po słowie. Transformer analizuje wszystkie tokeny wejścia równolegle. Oblicza dla każdego z nich wagi mechanizmu uwagi względem pozostałych elementów. Dzięki temu potrafi śledzić relacje między słowami oddalonymi o setki pozycji w tekście.
Tokenizacja i kontekst
Zanim model przetworzy zdanie, dzieli je na tokeny – podjednostki leksykalne mniejsze niż słowo (np. „pozycjonowanie” może być jednym lub kilkoma tokenami, zależnie od tokenizera). Flagowe modele z rodziny GPT-5 operują na oknie kontekstowym przekraczającym milion tokenów (wcześniejsze generacje GPT-4 były ograniczone do 128 000 tokenów). Milion tokenów to z grubsza obszerne repozytorium kodu albo kilka książek naraz. Oznacza to, że model „widzi” całą bieżącą rozmowę jednocześnie, bez konieczności „przypominania sobie” poprzednich kroków.
Każdy token jest zamieniany na wektor liczbowy w wielowymiarowej przestrzeni. Mechanizm uwagi (ang. attention mechanism) oblicza dla każdej pary tokenów stopień ich semantycznej zależności. Wynik to nie lista faktów, lecz matematyczna reprezentacja relacji między pojęciami. Właśnie dlatego model potrafi odpowiadać na pytania, których nigdy dosłownie nie widział w danych treningowych.
W uproszczeniu: kiedy piszesz „Jakie są zalety pracy zdalnej?”, model nie sięga po gotową odpowiedź. Rozkłada zapytanie na tokeny. Oblicza ich relacje ze wszystkimi kontekstami, jakie widział podczas treningu, a następnie generuje odpowiedź jako ciąg znaków o najwyższym łącznym prawdopodobieństwie. Każde słowo wpływa na prawdopodobieństwo kolejnego. To dlatego modele są nieprzewidywalne przy powtórzeniu tego samego pytania. Losowość jest wbudowana w sam mechanizm (parametr temperatury, ang. temperature, kontroluje, jak bardzo model „eksperymentuje” z rzadszymi tokenami).
Trening i dostosowanie do rozmowy
Sam etap wstępnego trenowania (pre-training) na terabajtach tekstu z internetu, książek i kodu tworzy potężny silnik predykcyjny. Generuje on równie sprawnie treści pomocne, co szkodliwe. OpenAI stosuje metodę RLHF (Reinforcement Learning from Human Feedback, czyli uczenie ze wzmocnieniem na podstawie ludzkich ocen), żeby ukierunkować model na dostarczanie użytecznych i bezpiecznych odpowiedzi.
Proces RLHF przebiega w trzech krokach. Po pierwsze, anotatorzy piszą przykładowe idealne odpowiedzi – model uczy się wzorca. Po drugie, ten sam model generuje kilka wariantów odpowiedzi na jedno pytanie, a ludzie szeregują je od najlepszej do najgorszej. Na tej podstawie trenowany jest oddzielny model oceniający (reward model). Po trzecie, algorytm PPO (Proximal Policy Optimization) aktualizuje wagi modelu tak, żeby maksymalizował oceny modelu nagradzającego, jednocześnie nie odchodząc za daleko od wyjściowego rozkładu probabilistycznego.
Efekt? Model nie tylko przewiduje prawdopodobny tekst, ale robi to w sposób, który ludzie oceniają jako pomocny i bezpieczny.
Plany i możliwości – co oferuje każda wersja
ChatGPT jest dostępny w kilku planach subskrypcyjnych. Zestawienie kluczowych różnic i limitów (stan na maj 2026) ułatwia wybór odpowiedniej wersji:
| Plan | Cena | Dostęp do modeli | Kluczowe funkcje |
|---|---|---|---|
| Free | 0 USD/mies. | GPT-5.5 Instant (z limitem) | Czat, podstawowe generowanie obrazów, tryb głosowy; w niektórych krajach z reklamami |
| Go | 8 USD/mies. | GPT-5.5 Instant | Plan dla codziennych użytkowników, wyższe limity niż Free |
| Plus | 20 USD/mies. | GPT-5.5, GPT-5.5 Thinking, GPT Image | Wyższe limity, Deep Research, Codex, priorytet w godzinach szczytu |
| Business | 25 USD/os./mies. | Jak Plus + priorytet dostępu | Przestrzeń zespołowa, izolacja danych od trenowania |
| Pro | 100–200 USD/mies. | GPT-5.5 Pro, Codex, brak limitów | Okno kontekstowe do 1 mln tokenów, rozszerzone limity Deep Research |
| Enterprise | Negocjowane | Jak Pro + opcje prywatne | SOC 2 Type II, SSO, niestandardowe retencje danych, wyższy limit kontekstu |
Plan Free wystarczy do testowania i zadań sporadycznych. Do regularnej pracy – szczególnie gdy liczy się jakość i brak ograniczeń w dostępie do asystentów AI (tzw. copilotów) – Plus pozostaje standardowym wyborem. Daje dostęp do flagowego GPT-5.5, wydanego 23 kwietnia 2026 roku. Plany Pro (warianty 100 i 200 USD) celują w zaawansowanych profesjonalistów i programistów. Rozszerzają okno kontekstowe do miliona tokenów i odblokowują GPT-5.5 Pro z najwyższym budżetem wnioskowania.
Do czego używać ChatGPT – zastosowania w praktyce
Użytkownicy nierzadko traktują ChatGPT jako klasyczną wyszukiwarkę. To błąd. Prowadzi do rozczarowań i ryzykownych decyzji biznesowych. ChatGPT sprawdza się tam, gdzie zadanie wymaga przetwarzania i transformacji tekstu, a nie tam, gdzie potrzebne są sprawdzone, bieżące fakty.
Obszary, w których model działa niezawodnie:
- Pisanie i redakcja – przeredagowanie tekstu, zmiana tonu, skracanie, tłumaczenie, korekta stylistyczna
- Programowanie – pisanie, debugowanie i tłumaczenie kodu; szczególnie mocne w popularnych językach (Python, JavaScript, SQL)
- Analiza dokumentów – wgranie pliku PDF lub arkusza i zadanie pytań o treść; ekstrakcja tabel, zestawień, kluczowych tez
- Burza mózgów – generowanie wariantów pomysłów, nazw, struktur artykułów, szkiców prezentacji
- Nauka – tłumaczenie skomplikowanych pojęć na prostszy język, generowanie przykładów, tworzenie fiszek
Obszary, w których należy zachować ostrożność:
- Fakty i aktualne dane – model ma datę odcięcia (cutoff date) i nie zna wydarzeń po niej; nawet przed datą odcięcia może „halucynować”, czyli generować w przekonujący sposób informacje nieprawdziwe
- Porady prawne, medyczne, finansowe – użyteczne jako wstępny zarys, nie jako substytut specjalisty
- Cytowania naukowe – model może wygenerować bibliografię, która wygląda wiarygodnie, ale w rzeczywistości nie istnieje
Granice możliwości tego narzędzia opisuje szczegółowo artykuł co potrafi ChatGPT, w którym znajdziesz praktyczne testy przypadków brzegowych.
Halucynacje – największe ograniczenie modelu
Halucynacja to sytuacja, w której model generuje odpowiedź syntaktycznie poprawną i sformułowaną w przekonujący sposób, ale merytorycznie błędną lub całkowicie wymyśloną. Termin ten wywodzi się z samej natury generowania. Model nie szuka faktów – przewiduje prawdopodobny ciąg tokenów. Jeśli kontekst skieruje go w stronę rzadkiego obszaru przestrzeni wag, wygeneruje coś, co brzmi jak fakt, choć wcale nim nie jest.
Halucynacje są szczególnie niebezpieczne, kiedy model podaje konkretne daty, nazwiska, tytuły publikacji lub ceny z absolutną pewnością. Oto kilka praktycznych reguł zmniejszających to ryzyko:
- Zawsze podawaj kontekst w pytaniu – im bardziej precyzyjne zapytanie, tym mniejsza swoboda modelu
- Weryfikuj liczby i cytowania zewnętrznie – każde twierdzenie z liczbą sprawdź w niezależnym źródle przed użyciem
- Wgrywaj dokumenty zamiast prosić o wiedzę z pamięci – model operujący na wgranym pliku halucynuje znacznie rzadziej niż odpowiadający z danych treningowych
- Stosuj technikę chain-of-thought – poproś model, żeby „myślał głośno” krok po kroku; przekierowanie uwagi na rozumowanie redukuje błędy faktyczne
Generowanie wspomagane wyszukiwaniem (RAG – Retrieval-Augmented Generation) to architektoniczne rozwiązanie tego problemu stosowane przez Perplexity i Google AI Overviews. Zamiast polegać wyłącznie na danych treningowych, model dynamicznie pobiera fragmenty stron i dopiero na ich podstawie generuje odpowiedź. ChatGPT z włączoną opcją wyszukiwania działa podobnie, choć sam mechanizm jest wewnętrznie inny.
ChatGPT a pozycjonowanie Twojej marki w AI
Rosnąca liczba użytkowników, którzy zamiast Google wpisują pytania bezpośrednio w ChatGPT, tworzy zupełnie nową kategorię widoczności. Dane Wall Street Journal z połowy 2025 roku pokazują, że 5,6% wszystkich zapytań w USA trafia już do LLM jako podstawowego narzędzia. Z kolei Gartner prognozuje, że do 2026 roku tradycyjne wyszukiwarki stracą 25% ruchu na rzecz interfejsów konwersacyjnych.
Jeśli potencjalny klient pyta „Które agencje SEO w Polsce specjalizują się w AI Search?”, to obecność Twojej marki w odpowiedzi zależy od kilku czynników. Czy Twoje treści były w korpusie treningowym modelu? Czy pojawiasz się w kontekście cytowań w wiarygodnych źródłach? Czy inne modele (z dostępem do internetu) Cię „widzą”? To zupełnie inne zmienne niż profil linków i zagęszczenie słów kluczowych, którymi rządzi się klasyczne SEO.
To nie jest SEO. To oddzielna dyscyplina z własnymi metrykami – Citation Rate, Share of Voice i Mention Rate.
Zrozumienie tych mechanizmów ułatwia przewodnik po GEO – optymalizacji pod generatywne wyszukiwarki. Jeśli interesuje Cię konkretna strona operacyjna, czyli jak ChatGPT postrzega Twoją markę i jak to zmienić, wejdź na pozycjonowanie w ChatGPT.
Zanim zaczniesz planować, sprawdź swój punkt startowy. Darmowe narzędzie Widoczność marki w AI zada zapytanie o Twoją markę czterem silnikom AI. Pokaże Ci, jak jesteś postrzegany na tle kategorii – całkowicie bez ręcznego testowania.





