

Spis treści
- Kim jest Anthropic i skąd wziął się Claude
- Jak działa Claude, czyli Constitutional AI zamiast zwykłego RLHF?
- Rodzina modeli Claude – Haiku, Sonnet, Opus
- Możliwości modelu Claude – co potrafi w praktyce
- Plany Claude.ai – Free, Pro, Max, Team, Enterprise
- Claude a konkurencja – mocne i słabe strony
- Jak Claude wpływa na widoczność marki w wynikach wyszukiwania AI?
- Bezpieczeństwo i Responsible Scaling Policy
Claude to duży model językowy (LLM – Large Language Model) tworzony przez firmę Anthropic – założoną w 2021 roku przez byłych badaczy OpenAI, z Dario i Danielą Amodei na czele. W odróżnieniu od konkurentów Anthropic zbudował Claude’a wokół koncepcji bezpieczeństwa jako fundamentu architektury, a nie tylko warstwy nakładanej na gotowy produkt. Zastanawiasz się, czy to coś więcej niż kolejny chatbot AI? Odpowiedź brzmi twierdząco – ten przewodnik wyjaśnia dokładnie mechanizmy jego działania.
Kim jest Anthropic i skąd wziął się Claude
Geneza firmy Anthropic wynika wprost z konfliktu wartości. W 2021 roku Dario Amodei, ówczesny wiceprezes ds. badań w OpenAI, opuścił firmę razem z grupą badaczy. Powód? Narastające spory o tempo komercjalizacji kosztem bezpieczeństwa. Wraz z siostrą Danielą i kilkoma współpracownikami – w tym Jaredem Kaplanem (dziś główny naukowiec) i Chrisem Olahiem (ekspert od interpretowalności sieci neuronowych) – zarejestrował Anthropic w San Francisco jako korporację pożytku publicznego (Public Benefit Corporation).
Statutowym celem firmy jest odpowiedzialny rozwój sztucznej inteligencji dla długoterminowego dobra ludzkości. To nie tylko pusty frazes w dokumentach rejestracyjnych. Firma stanowczo odmówiła podpisania kontraktów wymagających usunięcia klauzul zakazujących wykorzystywania modeli Claude do masowej inwigilacji czy autonomicznych systemów uzbrojenia. W 2026 roku doprowadziło to zresztą do głośnego konfliktu z Departamentem Obrony USA.
Pierwszy model Claude wszedł do publicznego użytku w marcu 2023 roku. Wcześniej firma przez blisko rok prowadziła wewnętrzne testy bezpieczeństwa. Zrezygnowała z branżowego standardu, czyli publikowania modelu i reagowania na problemy post factum. Wycena Anthropic osiągnęła w lutym 2026 roku ok. 380 miliardów dolarów.
Jak działa Claude, czyli Constitutional AI zamiast zwykłego RLHF?
Większość modeli językowych jest dostrajana metodą uczenia ze wzmocnieniem na podstawie opinii ludzi (RLHF – Reinforcement Learning from Human Feedback). Tysiące ewaluatorów przegląda odpowiedzi algorytmu i ocenia je, a model uczy się na tych ocenach. Przy wystarczająco złożonych zagadnieniach – takich jak specjalistyczny kod czy niuansowane dylematy etyczne – ludzka ocena staje się jednak wąskim gardłem.
Firma Anthropic poszła inną drogą i zbudowała framework zwany Constitutional AI (CAI). Zamiast polegać wyłącznie na ludzkich ewaluatorach, model uczy się z pomocą zestawu zasad – konstytucji – i koryguje własne odpowiedzi w oparciu o te wytyczne. Technicznie nazywa się to uczeniem ze wzmocnieniem na podstawie informacji zwrotnej od sztucznej inteligencji (RLAIF – Reinforcement Learning from AI Feedback).
Proces przebiega dwuetapowo. Najpierw model generuje ryzykowną odpowiedź, następnie ocenia ją względem konstytucji i pisze poprawioną wersję – ta para służy do dostrajania. Potem inny model analizuje pary odpowiedzi i generuje sygnał nagrody bez udziału człowieka. Wynikiem jest system, który zamiast bezrefleksyjnie odmawiać, potrafi wyjaśnić swoje ograniczenia i w miarę możliwości pomóc w alternatywny sposób.
Sama konstytucja Anthropic opiera się w ok. 50% na powszechnych zasadach praw człowieka, m.in. Powszechnej Deklaracji Praw Człowieka ONZ. Świadomie wyklucza reguły, co do których w społeczeństwie nie ma jasnego konsensusu.
Model zaufania – Operator, Użytkownik, Anthropic
Claude rozróżnia trzy poziomy zaufania w każdej rozmowie.
- Anthropic – najwyższy poziom, gdzie zasady są wbudowane w trening, a nie w prompt systemowy
- Operator – firma lub deweloper korzystający z API, który może rozszerzać lub zawężać domyślne zachowania Claude’a w ramach polityki Anthropic
- Użytkownik końcowy – osoba prowadząca rozmowę, domyślnie traktowana jako mniej zaufana niż operator
Ma to ogromne znaczenie praktyczne dla integratorów. Jeśli budujesz produkt na API Claude, możesz za pomocą promptu systemowego precyzyjnie określić, co model ma prawo robić w Twoim specyficznym kontekście.
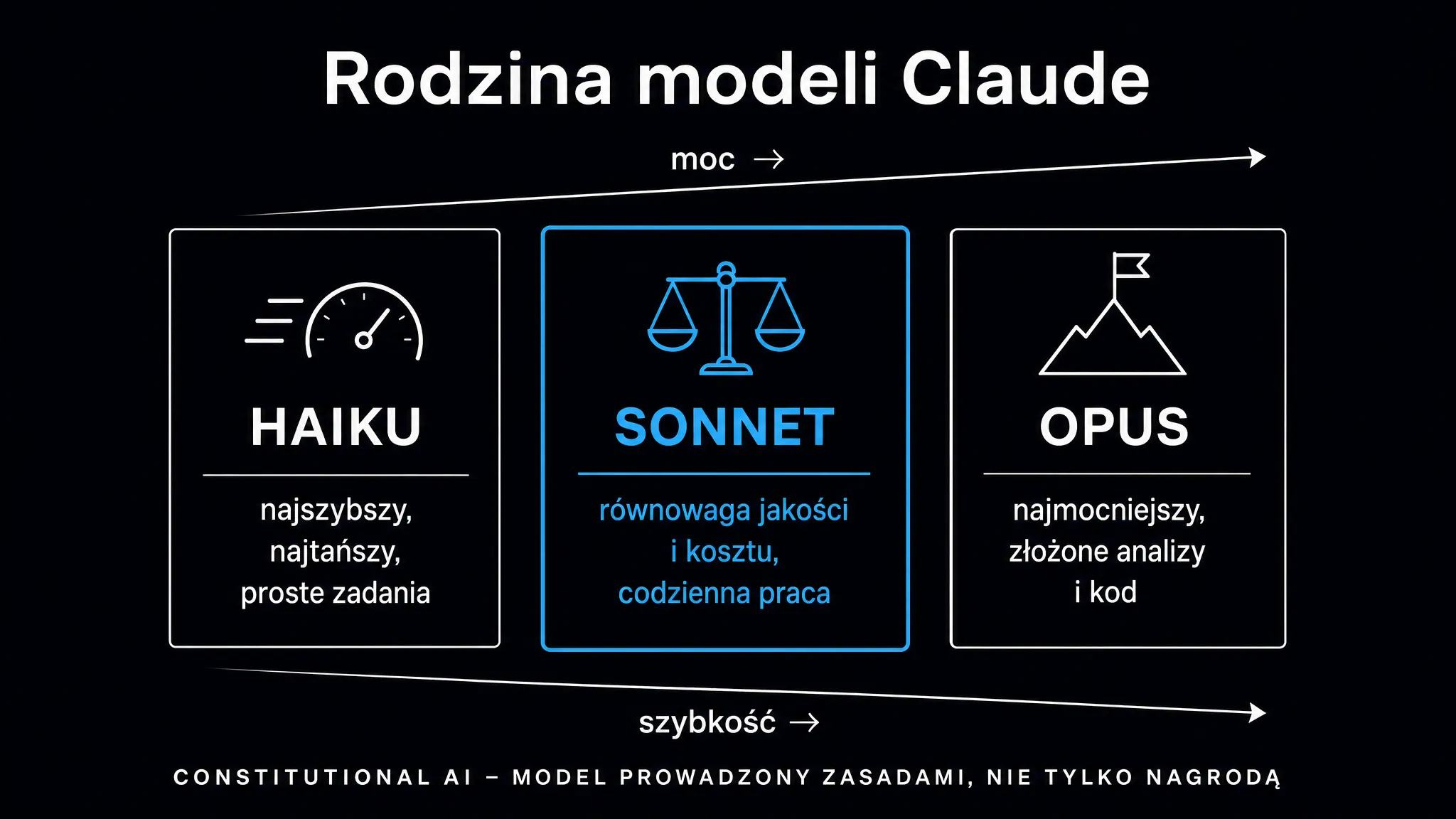
Rodzina modeli Claude – Haiku, Sonnet, Opus
Anthropic strukturyzuje swoje modele według trzech klas, różnicując je szybkością, zdolnościami i ceną. Pozwala to precyzyjnie dopasować model do konkretnego zadania bez przepłacania za niepotrzebną moc obliczeniową.
Zestawienie aktualnych klas modeli ułatwia wybór odpowiedniego wariantu (bez numerów wersji, które zmieniają się wraz z kolejnymi wydaniami).
| Klasa modelu | Przeznaczenie | Charakterystyka |
|---|---|---|
| Haiku | Zadania masowe, szybkie interakcje | Najniższy koszt w przeliczeniu na token, najkrótszy czas odpowiedzi, dobry do klasyfikacji, ekstrakcji danych i prostych Q&A |
| Sonnet | Balans zdolności i ceny | Optymalny do większości zadań biznesowych – analiza dokumentów, pisanie, asystent w aplikacjach |
| Opus | Złożone zadania analityczne | Najwyższe zdolności rozumowania, droższy, przeznaczony do wieloetapowych zadań agentowych i inżynierii oprogramowania |
Modele starsze o więcej niż dwie generacje są systematycznie wycofywane z API, co wymusza regularną aktualizację integracji. Tempo tego cyklu – nowa generacja co ok. 6 miesięcy – stanowi kluczowy czynnik przy planowaniu wdrożeń produkcyjnych.
Możliwości modelu Claude – co potrafi w praktyce
Claude w 2026 roku to znacznie więcej niż proste rozmowy tekstowe. Każda z dostępnych funkcji niesie za sobą konkretne implikacje dla integracji modelu w procesach firmowych.
Artifacts – interaktywne dokumenty w przeglądarce
Artifacts (artefakty) to funkcja pozwalająca Claude’owi generować interaktywną zawartość bezpośrednio w oknie rozmowy. Może to być kod HTML/CSS/JS, który natychmiast się renderuje, a także diagramy, arkusze kalkulacyjne czy dokumenty. Zamiast kopiować wynik do innego narzędzia, od razu widzisz działający prototyp w czasie rzeczywistym. To rozwiązanie sprawdza się idealnie przy tworzeniu prostych kalkulatorów, raportów w formacie tabeli czy interaktywnych wizualizacji danych.
Pojemne okno kontekstowe
Claude obsługuje okno kontekstowe rzędu 1 miliona tokenów (500 000 w interfejsie czatu, pełny milion przez API i Claude Code). W praktyce oznacza to możliwość wczytania całej dokumentacji technicznej projektu, kilkudziesięciu stron umowy lub obszernego zbioru danych. Następnie możesz prowadzić z nimi spójną rozmowę analityczną. To jeden z największych praktycznych kontekstów wśród komercyjnych modeli językowych na rynku.
Computer Use – sterowanie komputerem
Computer Use (sterowanie komputerem) pozwala Claude’owi obserwować ekran i symulować kliknięcia myszy oraz naciśnięcia klawiszy. Wszystko to bez konieczności integracji przez dedykowane API danej aplikacji. Model analizuje zrzut ekranu i podejmuje działania dokładnie tak, jak człowiek przy klawiaturze. Funkcja dostępna jest w planach Max i przez API, jednak z powodów bezpieczeństwa celowo ograniczono ją na platformach wyborczych i serwisach rządowych.
MCP – protokół kontekstu modelu
MCP (Model Context Protocol) to otwarty standard opracowany przez firmę Anthropic, który pozwala Claude’owi łączyć się z zewnętrznymi narzędziami i źródłami danych w sposób ustrukturyzowany. Dzięki MCP model potrafi czytać pliki z dysku, odpytywać bazy danych i wywoływać zewnętrzne API w ramach jednej spójnej sesji. Protokół ten skutecznie zastępuje wcześniejsze, niekompatybilne podejścia do integracji narzędzi. Coraz więcej platform (IDE, serwery CI/CD, CRM-y) oferuje już gotowe konektory MCP.
Claude Code – agent programistyczny
Claude Code to narzędzie CLI (interfejs wiersza poleceń) pozwalające modelowi na pełen odczyt i zapis repozytorium kodu bezpośrednio z terminala lub z poziomu edytora (VS Code, JetBrains). Model samodzielnie analizuje zależności w projekcie, uruchamia polecenia powłoki i naprawia błędy kompilacji. Dodatkowo pisze testy i tworzy gotowe gałęzie oraz żądania wciągnięcia (Pull Request). Jeśli szukasz przeglądu narzędzi agentowych do kodowania, przewodnik po modelach LLM opisuje szerszy kontekst rynkowy.
Plany Claude.ai – Free, Pro, Max, Team, Enterprise
Model Claude dostępny jest bezpośrednio przez interfejs claude.ai w kilku planach. Odpowiednie zestawienie parametrów pomoże Ci wybrać właściwy poziom subskrypcji.
| Plan | Dostęp do modeli | Charakterystyka |
|---|---|---|
| Free | Modele podstawowe (z limitami) | Bezpłatny; ograniczony dzienny limit wiadomości; bez Artifacts i Computer Use |
| Pro ($20/mies.) | Sonnet i Opus | Wyższe limity, priorytet w kolejce, dostęp do Artifacts |
| Max ($100–200/mies.) | Pełny dostęp, w tym Computer Use | Najwyższe limity, Computer Use, rozszerzone myślenie (extended thinking), kredyty API |
| Team | Modele Pro/Max | Współdzielone przestrzenie robocze, zarządzanie dostępem, udostępnianie projektów |
| Enterprise | Negocjowane | SSO, brak retencji danych (Zero Data Retention), SLA, dedykowane wdrożenia, zgodność z HIPAA/GDPR |
Opcja braku retencji danych (Zero Data Retention) w planie Enterprise oznacza, że żadne dane z zapytań nie są przechowywane przez serwery Anthropic po przetworzeniu. To absolutnie kluczowe dla organizacji objętych rygorystycznymi regulacjami branżowymi.
Claude a konkurencja – mocne i słabe strony
Claude nie jest najlepszy we wszystkich kategoriach, a uczciwe porównanie pomaga podjąć decyzję o doborze modelu. Jeśli interesuje Cię zestawienie z ChatGPT, artykuł o ChatGPT opisuje różnice w podejściu OpenAI do dostrajania i bezpieczeństwa. Z kolei Perplexity jako silnik z dostępem do sieci w czasie rzeczywistym omówiony jest w przewodniku po Perplexity.
Mocne strony Claude’a wynikające z realnych testów prezentują się następująco.
- Długi kontekst z zachowaniem uwagi – w testach MRCR v2 mierzących zdolność wydobywania szczegółów z milionowego kontekstu model Claude Opus osiągnął 76% trafnych odpowiedzi (Sonnet poprzedniej generacji – 18,5%)
- Złożone rozumowanie wieloetapowe – wyniki benchmarku Humanity’s Last Exam (zestaw 2500 zadań na granicy poznania naukowego, opublikowany przez Scale AI i Center for AI Safety w czasopiśmie Nature w styczniu 2026 roku) plasują flagowe modele Anthropic w ścisłej czołówce
- Bezpieczeństwo i transparentność – technologia Constitutional AI redukuje fałszywe pozytywne odmowy, a firma Anthropic co kwartał publikuje raport o ryzykach swoich modeli
Claude wypada jednak gorzej na tle konkurentów w kilku konkretnych obszarach.
- Szeroka obsługa wielu języków – GPT-4o wyprzedza Claude’a w przypadku rzadszych języków
- Bieżące informacje – Claude bez funkcji Computer Use posiada datę odcięcia wiedzy, podczas gdy Perplexity i Google AI Mode pobierają dane na żywo
- Koszt modelu Opus – najtańszym rozwiązaniem do masowego przetwarzania dużych wolumenów danych pozostaje Gemini Flash
Jak Claude wpływa na widoczność marki w wynikach wyszukiwania AI?
Jeśli Twoja marka pojawia się w odpowiedziach generowanych przez Claude’a – albo powinna, ale się nie pojawia – nie jest to kwestia przypadku. Claude, jak każdy model z dostępem RAG, pobiera treści ze stron internetowych. Następnie ocenia je pod kątem wiarygodności, spójności i gęstości informacji.
Strony dobrze zoptymalizowane pod GEO (Generative Engine Optimization, czyli optymalizację pod generatywne silniki wyszukiwania) są cytowane przez Claude’a częściej niż witryny z ogólnikową treścią bez twardych danych. Mechanizm ten działa identycznie jak ten opisany w przewodniku po GEO – statystyki, cytowania źródeł i ustrukturyzowane fragmenty podnoszą wskaźnik cytowań o 30–115% (Aggarwal et al., KDD 2024).
Chcesz sprawdzić, jak Twoja marka jest postrzegana przez Claude’a i inne modele? Narzędzie Widoczność marki w AI odpyta cztery silniki AI jednocześnie i pokaże różnice w odpowiedziach. Pełniejsza strategia widoczności marki w modelu Claude opisana jest na stronie pozycjonowanie AI – Claude.
Bezpieczeństwo i Responsible Scaling Policy
Firma Anthropic formalnie zarządza ryzykiem za pomocą ram (frameworku) Responsible Scaling Policy (RSP). Dokument ten w wersji 3.0 z 2026 roku precyzyjnie definiuje progi bezpieczeństwa powiązane z możliwościami modelu.
System opiera się na poziomach ASL (AI Safety Level).
- ASL-2 – standard dla wszystkich modeli komercyjnych obejmujący dokumentację bezpieczeństwa, testy penetracyjne (red-teaming) pod kątem podatności oraz mechanizmy zgłaszania luk
- ASL-3 – wdrażany, gdy model osiąga zdolności doradcze w dziedzinach CBRN (zagrożenia chemiczne, biologiczne, radiologiczne, jądrowe) lub gdy może autonomicznie replikować się bez nadzoru
- ASL-4 i wyżej – próg dla systemów, których niekontrolowany rozwój zagrażałby stabilności na skalę makroekonomiczną
Raz na kwartał Anthropic publikuje raport o ryzykach wszystkich aktywnych modeli. To bezprecedensowy poziom transparentności w branży, gdzie większość graczy traktuje testy bezpieczeństwa jako pilnie strzeżoną tajemnicę. Firma wyznaczyła też osobę na stanowisko Responsible Scaling Officer, by skutecznie koordynowała ten proces.





