

Spis treści
- Czym jest Perplexity i czym różni się od ChatGPT?
- Jak działa architektura RAG w Perplexity?
- Plany i funkcje – czym się różni Free od Pro i Max
- Spaces, Comet i ekosystem agentowy
- Jak Perplexity dobiera źródła i co wiemy o jego algorytmie selekcji?
- Perplexity jako kanał GEO – jak optymalizować pod ten silnik
Perplexity to nie kolejny chatbot, lecz wyszukiwarka zbudowana wokół cytowań, która w czasie rzeczywistym przeczesuje internet, syntetyzuje dziesiątki źródeł i odpowiada z przypisami. Od założenia w sierpniu 2022 roku platforma urosła do ponad 100 milionów aktywnych użytkowników miesięcznie i wyceny 20 miliardów dolarów (stan na początek 2026 roku). Dla specjalistów SEO i marketerów B2B to dziś jeden z najważniejszych kanałów dotarcia. Jeśli Twoja marka nie pojawia się w jego odpowiedziach, tracisz widoczność u osób aktywnie szukających rozwiązań w Twojej niszy. Z tego artykułu dowiesz się, jak Perplexity działa pod maską, skąd czerpie źródła i co zrobić, by bot zaczął cytować Twoją domenę.
Czym jest Perplexity i czym różni się od ChatGPT?
Perplexity to silnik odpowiedzi (answer engine) – kategoria narzędzi stojąca w rozkroku między klasyczną wyszukiwarką a asystentem AI. Zamiast zwracać listę linków, system syntetyzuje informacje z kilkunastu aktualnych źródeł i prezentuje jedną spójną odpowiedź z numerowanymi przypisami.
Różnica w stosunku do ChatGPT i Claude polega na architekturze. Tamte modele w trybie offline opierają się na wiedzy zamkniętej w parametrach sieci neuronowej. To wiedza ograniczona datą zakończenia trenowania, nierzadko z kilkunastomiesięcznym opóźnieniem. Perplexity za każdym razem uruchamia pobieranie danych z sieci, zanim wygeneruje odpowiedź. Każde zapytanie to żywy proces: szukaj, pobierz, zsyntetyzuj, zacytuj.
Właśnie ta architektura sprawia, że Perplexity odgrywa kluczową rolę w kontekście pozycjonowania w AI. Twoja strona musi być technicznie dostępna dla PerplexityBot. Co więcej, powinna zawierać treść, którą silnik z łatwością wyekstrahuje jako gotową odpowiedź, a nie tylko potraktuje jako tło.
Krótka historia – od bota na Twitterze do 20 miliardów dolarów
Firma powstała w sierpniu 2022 roku w San Francisco. Założył ją Aravind Srinivas (wcześniej OpenAI i Google DeepMind) wraz z Denisem Yaratsem, Johnnym Ho i Andym Konwinskim. Pierwszym prototypem był zautomatyzowany bot na Twitterze, który odpowiadał na pytania z przypisami do źródeł. Trafił w punkt. Użytkownicy chcieli konkretnych odpowiedzi, a nie niekończącej się listy linków.
Finansowanie rosło skokowo. We wrześniu 2022 roku zebrano 3,1 miliona dolarów w rundzie seed, a w grudniu 2024 roku wycena przekroczyła 9 miliardów dolarów przy rundzie prowadzonej przez IVP. Do początku 2026 roku spółka zebrała łącznie 1,5 miliarda dolarów, a do inwestorów dołączyli Nvidia, Jeff Bezos i SoftBank Vision Fund 2. W maju 2026 roku powtarzalny przychód roczny (ARR) przekroczył 500 milionów dolarów, rosnąc o 335% rok do roku.
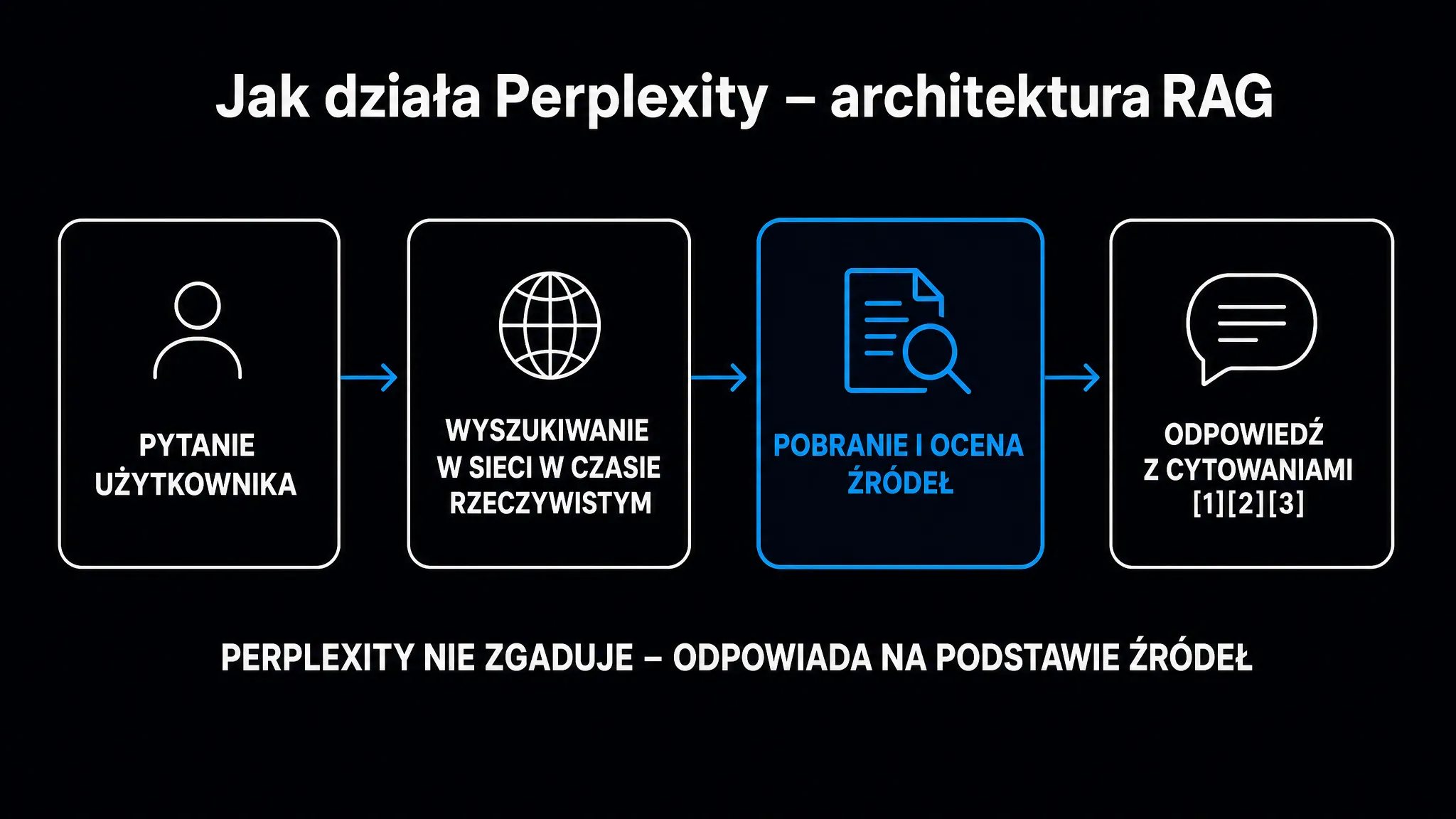
Jak działa architektura RAG w Perplexity?
Perplexity opiera się na architekturze RAG – generowania wspomaganego wyszukiwaniem (Retrieval-Augmented Generation). To podejście łączy klasyczny silnik wyszukiwania z modelem językowym. Najpierw pobiera aktualne dane z sieci, a dopiero potem generuje na ich podstawie odpowiedź.
Kiedy wpisujesz zapytanie, pod maską dzieje się kilka rzeczy naraz. Mniejszy model pomocniczy rozkłada je na zoptymalizowane frazy wyszukiwania. Własne boty indeksujące Perplexity (publikowane pod identyfikatorem PerplexityBot) oraz integracje z zewnętrznymi API przeszukują aktualne zasoby sieci. System wyodrębnia z pobranych stron krótkie, kontekstowo gęste fragmenty. Następnie zamienia je na reprezentacje wektorowe (tzw. embeddingi) i wybiera te, które semantycznie najlepiej odpowiadają pytaniu. Dopiero wyselekcjonowane fragmenty trafiają do głównego modelu językowego jako kontekst. Na samym końcu model generuje odpowiedź z przypisami do oryginalnych źródeł.
Kluczowa informacja dla specjalistów SEO: Perplexity nie czyta strony jako całości, lecz dzieli tekst na fragmenty o długości 200–400 słów i ocenia każdy z nich osobno. Fragmenty z liczbami, datami, definicjami i nazwami własnymi mają wyższy priorytet przy selekcji. To oznacza, że strona z ogólnikowymi opisami jest dla tego silnika całkowicie bezużyteczna. Nawet jeśli zajmuje wysokie pozycje w Google.
Jakie modele LLM wykorzystuje Perplexity
Perplexity nie jest pojedynczym modelem. To warstwa nadrzędna zarządzająca kilkoma zewnętrznymi modelami językowymi. W zależności od planu i trybu użytkownik może korzystać z modeli rodziny GPT (OpenAI), Claude (Anthropic), Gemini (Google) oraz autorskich modeli Perplexity z serii Sonar. Te ostatnie bazują na architekturze open-source Llama od Meta, ale zespół Perplexity dostroił je ściśle pod kątem odpowiedzi opartych na danych z sieci.
Dla marketerów i specjalistów SEO płynie stąd ważny wniosek. Ta sama marka może być cytowana lub pomijana przez różne modele pracujące w tym samym interfejsie, ponieważ każdy z nich ma inne wzorce selekcji źródeł. Widoczność w Perplexity to w istocie widoczność w kilku silnikach jednocześnie.
Plany i funkcje – czym się różni Free od Pro i Max
Perplexity oferuje trzy główne poziomy dostępu. Poniższe zestawienie pokazuje kluczowe różnice między nimi:
| Plan | Cena (mies.) | Główne możliwości | Limit zapytań Pro |
|---|---|---|---|
| Free | 0 USD | Standardowe wyszukiwanie z przypisami, wybrane modele | ~5 zapytań Pro dziennie |
| Pro | 20 USD | Nieograniczone zapytania, GPT-5 / Claude Opus 4, wgrywanie plików PDF | Bez limitu |
| Max | 200 USD | Model Council, Deep Research bez limitu, priorytetowy dostęp | Bez limitu + kredyty compute |
| Enterprise | Kontakt | RAG na prywatnych danych firmowych, prywatność danych, SSO | Indywidualny |
Plan Pro w zupełności wystarczy większości marketerów i specjalistów SEO. Z kolei Plan Max stworzono z myślą o zaawansowanych analizach. Daje on dostęp m.in. do funkcji Model Council (Rada Modeli), która wysyła zapytanie równolegle do trzech różnych modeli i porównuje ich odpowiedzi, precyzyjnie wskazując punkty zgodności i rozbieżności.
Deep Research – zautomatyzowana analiza wieloetapowa
Deep Research (głębokie badanie) to tryb, w którym Perplexity autonomicznie planuje i wykonuje serię podzapytań, przegląda od kilkunastu do kilkudziesięciu źródeł, a na koniec generuje raport z pełnym aparatem bibliograficznym. Dla analityków B2B to potężne narzędzie, które z powodzeniem zastępuje kilka godzin manualnego przeglądania raportów i artykułów.
W kontekście GEO tryb Deep Research jest szczególnie interesujący, ponieważ model cytuje tu proporcjonalnie więcej źródeł niż przy standardowym zapytaniu. Jeśli Twoja strona pojawia się w kilku miejscach jako autorytatywne źródło w danej niszy, algorytm ma ogromną szansę ją zacytować.
Spaces, Comet i ekosystem agentowy
Perplexity dynamicznie ewoluuje w kierunku platformy agentowej. Dwa elementy są tu szczególnie istotne dla zaawansowanych użytkowników.
Spaces (Przestrzenie) to wyspecjalizowane obszary robocze, w których możesz:
- Zapisywać niestandardowe instrukcje – np. „odpowiadaj jako konsultant B2B SaaS, używaj danych z europejskiego rynku”
- Gromadzić kontekst projektowy – dokumenty PDF, notatki i historia konwersacji w jednym miejscu
- Współpracować zespołowo – Spaces udostępnisz bez problemu innym członkom zespołu
Comet to przeglądarka webowa zbudowana przez Perplexity do obsługi zadań agentowych. Zamiast szukać informacji i czekać na polecenie, Comet potrafi autonomicznie nawigować po stronach, wypełniać formularze i wykonywać sekwencje działań w imieniu użytkownika. W lutym 2026 roku Perplexity uruchomiło środowisko Computer. To głębsza integracja asystenta z systemami operacyjnymi urządzeń mobilnych i desktopowych, wzbogacona o wielomodalną analizę otoczenia przez kamerę i zarządzanie zadaniami między aplikacjami.
Dla specjalistów SEO ten kierunek oznacza jedno. Perplexity przestaje być wyłącznie kanałem informacyjnym, a staje się kanałem wykonawczym. Marki cytowane w Spaces i agentowych przepływach pracy zyskają obecność na samym etapie decyzji zakupowej, a nie tylko w fazie researchu.
Jak Perplexity dobiera źródła i co wiemy o jego algorytmie selekcji?
Perplexity nie ujawnia pełnego algorytmu selekcji źródeł. Z obserwacji praktycznych i dokumentacji technicznej wyłania się jednak kilka twardych reguł, które po prostu musisz znać.
Pierwsza zasada to aktualność. Perplexity faworyzuje strony opublikowane lub zaktualizowane niedawno, co widać szczególnie przy zapytaniach o bieżące wydarzenia, ceny czy dane rynkowe. Strona z datą modyfikacji sprzed kilku lat ma drastycznie mniejszą szansę na cytowanie w odpowiedziach, w których czas odgrywa rolę.
Druga zasada to semantyczna zgodność fragmentu z zapytaniem. Boty nie indeksują stron jako całości, lecz pobierają fragmenty i porównują ich reprezentacje wektorowe z wektorem zapytania. Strona z jednym ogólnym artykułem o „marketingu AI” z góry przegrywa z serią krótkich, konkretnych tekstów odpowiadających na jedno pytanie naraz. Długość optymalnego fragmentu wynosi 200–400 słów i musi on posiadać wyraźny nagłówek.
Trzecia zasada to autorytet domeny i wzajemne cytowania. Perplexity znacznie chętniej sięga do źródeł wzmiankowanych przez inne indeksowane strony – działa to na podobnej zasadzie jak ocena PageRank w Google. Obecność w raportach branżowych, Wikipedii czy prestiżowych mediach mocno winduje szansę na uwzględnienie Twojej domeny przez silnik.
Czwarta zasada to struktura tekstu. Fragmenty zawierające tabele, listy definicji oraz dane liczbowe z datą i źródłem są wyraźnie preferowane przez silniki RAG. Potwierdza to badanie Aggarwala i in. (KDD 2024), które udokumentowało wzrost wskaźnika cytowań o 30–41% po dodaniu statystyk i twardych danych do treści.
Perplexity a prawa autorskie wydawców
Perplexity od 2024 roku zmaga się z pozwami wydawców. Dow Jones & Company (wydawca „Wall Street Journal”) oraz grupy medialne takie jak BBC i „New York Times” twierdzą, że boty pobierały treści z naruszeniem pliku robots.txt i reprodukowały obszerne fragmenty artykułów bez licencji. W sierpniu 2025 roku federalny sąd w Nowym Jorku odrzucił wnioski Perplexity o oddalenie sprawy na etapie formalnym, co oznacza, że trafi ona do sądu przysięgłych. Równolegle firma buduje program podziału przychodów z wydawcami w proporcji 80/20 (80% dla wydawcy).
Dla marketerów płynie z tego bardzo praktyczna konkluzja. Model prawny, na którym operuje Perplexity, pozostaje wciąż mocno niestabilny. Warto na bieżąco monitorować, jakie zmiany w polityce cytowań przyniosą kolejne orzeczenia sądowe. Mogą one bezpośrednio wpłynąć na to, które domeny będą chętniej cytowane w wynikach.
Perplexity jako kanał GEO – jak optymalizować pod ten silnik
Perplexity stanowi naturalny most do GEO (Generative Engine Optimization, optymalizacja pod generatywne silniki wyszukiwania). Ponieważ każda odpowiedź zawiera widoczne cytowania, mówimy o jednym z nielicznych silników AI, w którym empirycznie zmierzysz wskaźnik cytowań (Citation Rate) własnej marki bez użycia specjalistycznych narzędzi.
Zastosuj cztery kroki do lepszej widoczności w Perplexity:
- Dostęp techniczny – sprawdź, czy
PerplexityBotnie jest blokowany przezrobots.txtani przez reguły zapory sieciowej Cloudflare; zweryfikujesz to w Dostęp botów AI w zaledwie kilka sekund - Struktura fragmentów – podziel treść na samodzielne bloki o długości 200–400 słów, z których każdy ma nagłówek w formie pytania i odpowiedź w pierwszym zdaniu; pamiętaj, że silnik RAG ocenia każdy fragment oddzielnie
- Gęstość faktograficzna – dodaj do każdej sekcji H2 co najmniej jedną liczbę z datą i źródłem; fragmenty nasycone danymi liczbowymi mają wyższy priorytet przy selekcji wektorowej
- Wzajemne wzmianki – buduj obecność w miejscach, z których Perplexity chętnie czerpie wiedzę, takich jak branżowe raporty, Wikipedia, fora Reddit czy media B2B; to silny sygnał autorytetu dla algorytmu selekcji
Szczegółowe wskazówki dotyczące zwiększania wskaźnika cytowań znajdziesz w naszym przewodniku po tym, jak LLM-y cytują źródła. Z kolei szeroką perspektywę na całą dyscyplinę GEO zyskasz, zaglądając do kompletnym przewodniku GEO.





