

Spis treści
- SWE-bench Verified – co mówi najbardziej wymagający punkt odniesienia
- Claude Code vs Codex – dwa różne modele pracy agentowej
- Tabela porównawcza – modele, narzędzia, ceny, benchmarki
- Jakość kodu w praktyce – gdzie naprawdę widać różnicę
- Agentowe przepływy pracy – MCP, Function Calling i integracje
- Ceny API i koszt w agentowych sesjach
- Werdykty dla poszczególnych scenariuszy
Jeśli piszesz kod produkcyjny z pomocą dużego modelu językowego (LLM – Large Language Model), wybór między Claude a ChatGPT przekłada się bezpośrednio na jakość kodu, koszty API i czas spędzony na poprawkach. Na syntetycznych zadaniach oba modele osiągają ponad 90% na HumanEval. Ten benchmark jest od lat nasycony. Prawdziwa różnica wychodzi na SWE-bench Verified, czyli zestawie realnych błędów z GitHuba, oraz w agentowych narzędziach Claude Code i Codex, które operują na całym repozytorium. Porównajmy oba ekosystemy technicznie, by wyłonić zwycięzców dla konkretnych scenariuszy.
SWE-bench Verified – co mówi najbardziej wymagający punkt odniesienia
SWE-bench Verified to dziś najtrudniejsza publicznie dostępna miara zdolności kodowania modeli AI. Zamiast pisać nową funkcję od zera, model musi przeanalizować istniejące repozytorium Pythona, zlokalizować przyczynę błędu opisaną w zgłoszeniu (tickecie) z GitHuba i wygenerować łatkę. Ta musi przejść testy automatyczne. Z 500 zweryfikowanych przez człowieka problemów korzysta wiele niezależnych laboratoriów. Wyniki są więc w pełni porównywalne między firmami.
Aktualne wyniki na maj 2026 roku pokazują silną przewagę Anthropic w tej kategorii. Claude Opus 4.5 był pierwszym modelem, który przekroczył próg 80%, osiągając 80,9% – przy GPT-5.1 na poziomie 76,3%. Najnowszy Claude Opus 4.8, wydany 28 maja 2026 roku, uzyskał 88,6% (poprzedni Opus 4.7 – 87,6%), a wciąż eksperymentalny Claude Mythos Preview – 93,9% (dane: BenchLM.ai). Po stronie OpenAI GPT-5.5 w konfiguracji Codex osiągnął ~88,7% według zewnętrznych trackerów. Z kolei na trudniejszym SWE-bench Pro zanotował 58,6% (gdzie Claude Opus 4.8 prowadzi z wynikiem 69,2%, wobec 64,3% dla Opus 4.7).
Co te liczby znaczą w praktyce? SWE-bench wymaga analizy wielu plików jednocześnie. Model musi śledzić zależności między modułami, zrozumieć historię zmian i napisać łatkę, która nie wywali innych testów. To dokładnie ten typ pracy, który zajmuje programistom długie godziny.
HumanEval i MBPP – gdzie benchmarki przestają rozróżniać modele
Na HumanEval (generowanie funkcji Pythona z opisu w języku naturalnym) Claude 3.5 Sonnet i GPT-4o osiągają odpowiednio 92% i 90,2%. Przy takich wynikach różnica zaciera się w codziennym użyciu. Dla prostych zadań generowania kodu oba modele są praktycznie równoważne – wybór zależy wtedy od ekosystemu, a nie od zdolności modelu.
Nasycenie HumanEval przez wiodące modele sprawiło, że branża przeniosła się na trudniejsze benchmarki. Na SWE-bench Pro – zestawie bardziej złożonych, wieloplikowych problemów – rozstrzał między modelami rośnie. To właśnie tutaj widać rzeczywistą przewagę Claude’a w złożonym rozumowaniu nad kodem. Pełny profil możliwości modelu i jego historię opisuje artykuł o Claude, a odpowiednik po stronie OpenAI – artykuł o ChatGPT.
Claude Code vs Codex – dwa różne modele pracy agentowej
Claude Code i Codex (narzędzie OpenAI) to agentowe interfejsy CLI (interfejsy wiersza poleceń) do pracy z całym repozytorium. Oba modele potrafią czytać pliki, uruchamiać testy, tworzyć gałęzie i proponować pull requesty. Robią to jednak w fundamentalnie inny sposób.
Claude Code działa lokalnie. Instalujesz go za pomocą skryptu instalacyjnego, programu brew lub winget (instalacja przez npm została oznaczona jako przestarzała). Wskazujesz katalog projektu, a narzędzie operuje bezpośrednio na Twoich plikach. Czyta całą strukturę repozytorium, uruchamia polecenia w powłoce systemowej, naprawia błędy kompilacji i zatwierdza zmiany (tworzy commity) do gita. Model ma pełny odczyt i zapis. Daje mu to kontekst niedostępny dla narzędzi bazujących na zrzutach ekranu czy selekcji fragmentów kodu.
Codex działa w chmurze. Każde zadanie uruchamia się w izolowanym kontenerze wirtualnym po stronie OpenAI. To architektura preferowana przy równoległym delegowaniu wielu zadań. Codex może obsługiwać kilka zgłoszeń jednocześnie, bez blokowania Twojego terminala. Wymaga jednak połączenia z internetem i operuje na snapshocie repozytorium, a nie na rzeczywistym środowisku.
Różnice w praktyce:
- Kontekst środowiskowy – Claude Code widzi Twoje zmienne środowiskowe, lokalne bazy danych i uruchomione serwisy, podczas gdy Codex operuje w sandboxie izolowanym od lokalnej infrastruktury
- Latencja – Claude Code reaguje natychmiast dzięki pracy lokalnej, natomiast Codex przesyła pliki do kontenera i z powrotem, co przy dużych projektach dodaje kilkanaście sekund
- Bezpieczeństwo kodu – Codex nie widzi lokalnych kluczy API ani haseł w
.env, za to Claude Code widzi wszystko w systemie plików - Równoległość – Codex wyprzedza tutaj konkurenta wyraźnie, ponieważ Claude Code jest z natury sekwencyjny
Jeśli chcesz głębiej zrozumieć, jak agentowe narzędzia do kodowania wpisują się w szerszy ekosystem automatyzacji, przewodnik po agentach AI opisuje architekturę wieloagentowych przepływów pracy.
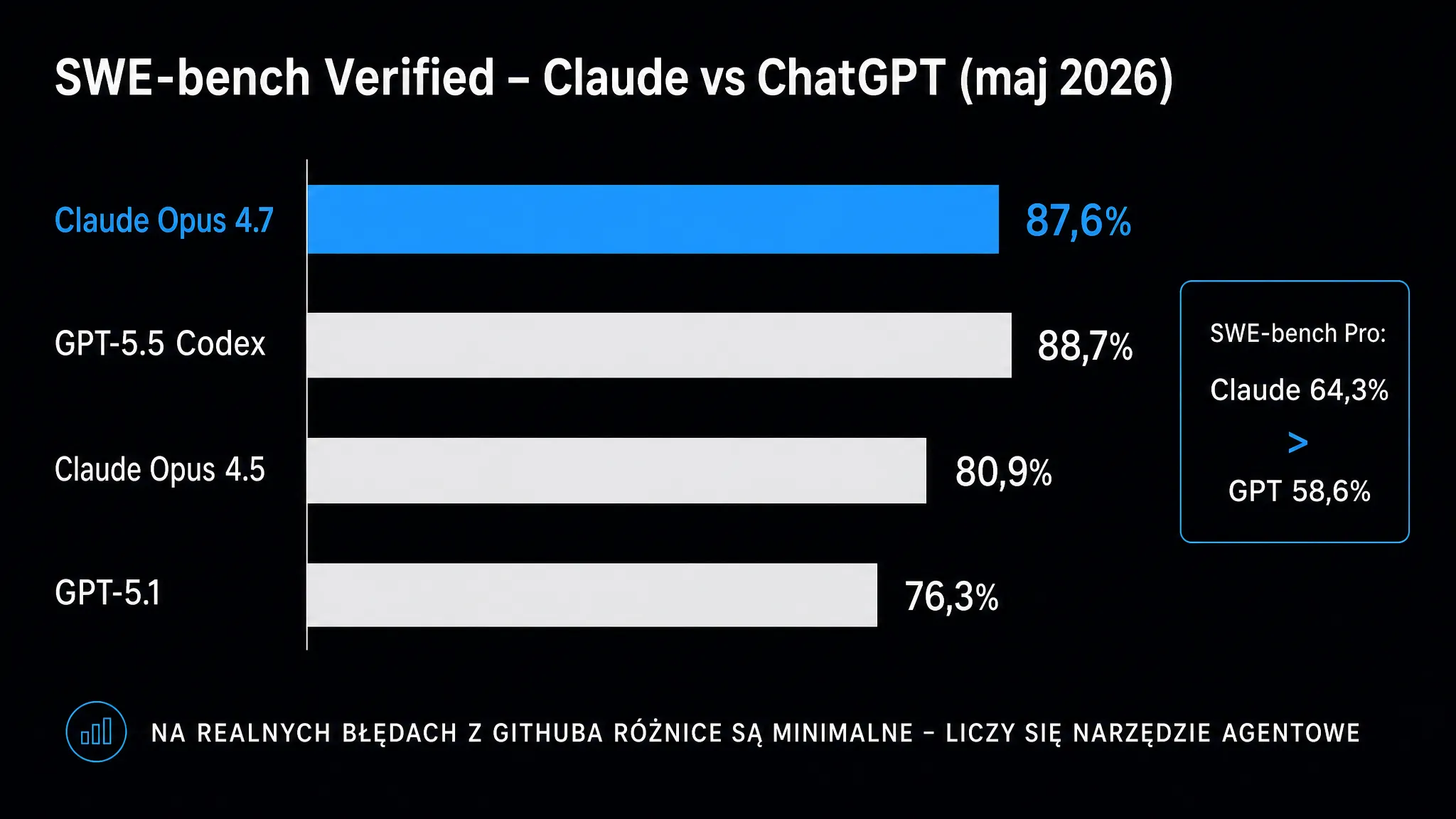
Tabela porównawcza – modele, narzędzia, ceny, benchmarki
Zestawienie najważniejszych parametrów obu ekosystemów na maj 2026 roku ułatwia podjęcie decyzji. Ceny API podane są dla wejścia i wyjścia w przeliczeniu na milion tokenów.
| Parametr | Claude (Anthropic) | ChatGPT / Codex (OpenAI) |
|---|---|---|
| SWE-bench Verified (flagship) | 88,6% (Opus 4.8) | ~88,7% (GPT-5.5 + Codex) |
| SWE-bench Pro (flagship) | 69,2% (Opus 4.8) | 58,6% (GPT-5.5) |
| HumanEval (mid-tier) | 92% (Sonnet 3.5) | 90,2% (GPT-4o) |
| Cena API – balans (in/out) | $3/$15 za 1M tokenów (Sonnet 4.6) | $2,50/$15 za 1M tokenów (GPT-5.4) |
| Cena API – flagship (in/out) | $5/$25 za 1M tokenów (Opus 4.8) | $5/$30 za 1M tokenów (GPT-5.5) |
| Cena API – ekonomiczny | $1/$5 za 1M tokenów (Haiku 4.5) | $0,75/$4,50 za 1M tokenów (GPT-5.4 Mini) |
| Okno kontekstowe | 1 000 000 tokenów | 1 050 000 tokenów (GPT-5.5) |
| Agent CLI | Claude Code (lokalny) | Codex CLI (lokalny) + Codex web (chmura) |
| Tryb wykonania agenta | lokalny (filesystem) | hybrydowy (lokalny CLI + chmurowy kontener) |
| Dostęp do narzędzi | MCP (otwarty standard) | Function Calling, Responses API |
| Plan subskrypcji z agentem | Pro ($20/mies.) lub Max ($100–200/mies.) | ChatGPT Plus ($20/mies.) lub Pro ($100–200/mies.) |
| Prompt caching | tak – $0,30/1M tokenów (Sonnet 4.6) | tak – $0,50/1M tokenów (GPT-5.5, cached input) |
Warto doprecyzować kilka kwestii. Choć zbalansowany GPT-5.4 kosztuje nominalnie mniej na tokenach wejściowych niż Sonnet 4.6, Claude oferuje bardziej efektywne buforowanie zapytań (prompt caching). Przy długich sesjach agentowych, gdzie ten sam kontekst projektu przesyła się wielokrotnie, koszt pojedynczego żądania mocno spada. Może być zbliżony do tańszych modeli lub wręcz przemawiać na korzyść Claude’a. Z kolei koszt flagowego GPT-5.5 to wydatek rzędu $5/$30. Dla intensywnych agentowych przepływów pracy szacowany rzeczywisty koszt miesięczny w Anthropic wynosi $10–80 na programistę, co jest wynikiem porównywalnym lub korzystniejszym w zestawieniu z ekwiwalentem w OpenAI przy zbliżonym wykorzystaniu.
Jakość kodu w praktyce – gdzie naprawdę widać różnicę
Benchmarki to mierzalny punkt wyjścia. W codziennej pracy programistów powtarzają się jednak inne obserwacje. Nie trafiają one do tabel, a bywają decydujące przy wyborze narzędzia.
Claude wyróżnia się w złożonych refaktoryzacjach, gdzie konieczne jest śledzenie zależności przez wiele plików jednocześnie. Milionowe okno kontekstowe to nie tylko marketing. Model potrafi wczytać całe repozytorium średniej wielkości (do ~700 tys. tokenów kodu), przeanalizować historię zmian i zaproponować refaktoryzację spójną z istniejącymi wzorcami. Warto jednak zaznaczyć, że w 2026 roku OpenAI nadrobiło te zaległości. GPT-5.5 również dysponuje oknem powyżej miliona tokenów (w przeciwieństwie do starszego GPT-4o, który bywał zmuszony do wycinania kontekstu lub korzystania ze strategii streszczania, przez co traciło się szczegóły).
Z kolei ChatGPT i GPT-5.5 pokazują przewagę przy generowaniu kodu szablonowego (boilerplate) i pracy z mniej popularnymi frameworkami. Ekosystem OpenAI jest rozleglejszy, a model widywał więcej różnorodnego kodu w danych treningowych. Jeśli piszesz szybki skrypt w niszowej bibliotece, Codex często proponuje działający prototyp już w pierwszej iteracji.
Przy pracy w językach innych niż angielski różnica jest mniejsza, ale wciąż widoczna. Modele OpenAI radzą sobie lepiej z generowaniem komentarzy i dokumentacji po polsku. Dla samego kodu (logika, algorytmy, architektura) język naturalny nie ma oczywiście żadnego znaczenia.
Agentowe przepływy pracy – MCP, Function Calling i integracje
Oba ekosystemy oferują mechanizmy łączenia modelu z zewnętrznymi narzędziami. Podchodzą jednak do tego problemu zupełnie inaczej.
Claude dostarcza MCP (Model Context Protocol) – otwarty standard, który pozwala modelowi łączyć się z zewnętrznymi źródłami danych i narzędziami przez ustrukturyzowany protokół. MCP jest niezależny od producenta. Możesz zbudować konektor MCP do własnej bazy danych, wewnętrznego narzędzia CI/CD czy systemu zgłoszeń i używać go z Claude’em bez modyfikacji. Coraz więcej platform (IDE, serwery CI, CRM-y) dostarcza gotowe konektory tego typu.
OpenAI idzie drogą Function Calling i Responses API. To ścieżka bardziej dojrzała technologicznie, z większą bazą gotowych integracji w zewnętrznych bibliotekach. Ekosystem ChatGPT Plugins i GPT Store, mimo zawirowań w 2025 roku, wciąż oferuje tysiące gotowych wtyczek.
Kluczowa różnica dla zespołów budujących własne narzędzia sprowadza się do otwartości. MCP jest przenośny między dostawcami, podczas gdy Function Calling to de facto standard branżowy z lepszym wsparciem w bibliotekach open source (LangChain, LlamaIndex, AutoGen). Jeśli Twój stos technologiczny (stack) opiera się na frameworkach agentowych, Function Calling zapewni Ci gotowe konektory. MCP jest nowszy i jego wsparcie rośnie, ale wciąż musi doganiać konkurencję.
Architekturę wieloagentowego przepływu pracy z użyciem obu ekosystemów opisuje szerzej przewodnik po modelach LLM – z omówieniem tego, kiedy warto mieszać modele zamiast polegać na jednym.
Ceny API i koszt w agentowych sesjach
Surowe ceny tokenów to tylko część rachunku. Przy agentowych przepływach pracy model wykonuje dziesiątki zapytań na zadanie, a każde z nich zawiera pełny kontekst projektu w prefiksie. To właśnie tutaj mechanizmy buforowania (prompt caching) decydują o tym, ile naprawdę zapłacisz.
Anthropic oferuje prompt caching dla Sonnet 4.6 za $0,30/1M tokenów wejściowych (przy oryginalnej cenie $3). To 10-krotna redukcja kosztów dla tych samych tokenów kontekstowych. W typowej sesji Claude Code, gdzie systemowy kontekst projektu (pliki konfiguracyjne, główne moduły) jest wielokrotnie przesyłany, oszczędność na promptach może wynosić 60–75% względem ceny nominalnej.
Dla OpenAI cached input GPT-5.5 kosztuje $0,50/1M tokenów (10% ceny standardowej, naliczane automatycznie). To wciąż nieco drożej niż buforowany Sonnet. Po przeliczeniu rzeczywistego kosztu na sesję modele wychodzą jednak bardzo blisko siebie.
Przykładowe szacunki miesięczne na programistę:
- Lekkie użycie (skrypty, eksperymenty) – Claude Sonnet: ~$5–15, GPT-5.4 Mini: ~$4–12
- Regularna praca (daily coding assistant) – Claude Sonnet: ~$15–35, GPT-5.4: ~$12–30
- Intensywna praca z agentami (Claude Code / Codex, cały dzień roboczy) – Claude Opus: ~$50–120, Codex w planie Pro: wliczone w $200/mies.
Subskrypcja ChatGPT Pro ($100–200/mies.) obejmuje dostęp do Codex i modeli GPT-5 bez dodatkowych opłat za token. Dla zaawansowanych użytkowników narzędzi agentowych może to być znacznie korzystniejsze niż model płatności za zużycie (pay-as-you-go) w Anthropic. Claude oferuje analogicznie plan Max ($100–200/mies.) z wyższymi limitami, ale rozliczenia tokenowe nadal obowiązują przy przekroczeniu puli.
Pełny przegląd modeli i ich pozycjonowania cenowego – razem z alternatywami ekonomicznymi dla różnych wolumenów użycia – zestawia przewodnik po modelach LLM dostępny w sekcji powyżej.
Werdykty dla poszczególnych scenariuszy
Oba narzędzia są wysoce kompetentne. Wybór zależy od charakteru pracy, a nie od tego, który model jest obiektywnie „lepszy”.
Scenariusze, w których Claude wygrywa wyraźnie:
- Duże refaktoryzacje wieloplikowe – milionowe okno kontekstowe pozwala na pracę z całym projektem bez przycinania kontekstu (truncation), a SWE-bench Verified potwierdza przewagę w złożonej analizie kodu
- Długie sesje analityczne – analiza architektury, przegląd (review) całej gałęzi czy migracje między frameworkami to zadania, w których Claude utrzymuje spójność kontekstu przez długie godziny pracy
- Praca z wewnętrznym stosem technologicznym – Claude Code z MCP łatwo integruje się z wewnętrznymi narzędziami przez otwarty protokół i nie wymaga gotowych wtyczek z katalogu
Scenariusze, w których ChatGPT / Codex wygrywa lub remisuje:
- Szybkie skrypty i kod szablonowy (boilerplate) – modele OpenAI mają duże doświadczenie z różnorodnymi frameworkami, dzięki czemu prototyp w niszowej bibliotece często działa od razu
- Równoległe zadania asynchroniczne – Codex w trybie chmurowym obsługuje wiele zgłoszeń jednocześnie w izolowanych kontenerach, podczas gdy Claude Code jest sekwencyjny
- Zespoły w ekosystemie OpenAI – jeśli używasz już GPT-5.5 w innych procesach, Codex CLI integruje się bez dodatkowej konfiguracji kont i kluczy API
- Dokumentacja i komentarze w języku polskim – modele z rodziny GPT generują czytelniejszy tekst w rzadszych językach
Przy budowaniu agentów AI opartych na uczeniu maszynowym oba modele oferują wystarczające możliwości. Wybór modelu bazowego to znacznie mniej ważna decyzja niż architektura samego agenta.
Jeśli dopiero wybierasz model do nowego projektu, skonfiguruj tymczasowy dostęp do obu ekosystemów. Przetestuj je na reprezentatywnym zadaniu ze swojego repozytorium. Różnica między modelami na Twoim konkretnym kodzie powie Ci więcej niż jakikolwiek benchmark.





